Deep Learning Practice - NLP
Adapting to Downstream Tasks:
Fine-tuning, Prompting, Instruction Tuning and Preference tuning
Mitesh M. Khapra, Arun Prakash A


AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Pre-Training
Minimize
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 12

Embedding Matrix
We trained the GPT-2 model with the CLM (Causal Language Modelling) training objective


Text generation
Classification
Conversation
However, how can we adapt it to different downstream tasks ?

sentiment, NER,..
QA, translate, summarize
Chat bot
One approach for using the pre-trained models for downstream tasks is to independently fine-tune the parameters of the model for each task
BERT, GPT,BART
Dataset
BERT, GPT,BART
BERT, GPT,BART
BERT, GPT,BART
That is, we make a copy of the pre-trained model for each task and fine-tune it on the dataset specific to that task
Pre-training
Fine-tuning
Standford Sentiment Tree Bank (SST)
SNLI
LAMBADA
Predict the last word of a Long sentence
Fine-tuning for Text Classfication
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 12
Embedding Matrix
Each sample in a labelled data set \(\mathcal{C}\) consists of a sequence of tokens \(x_1,x_2,\cdots,x_m\) with the label \(y\)
Initialize the parameters with the parameters learned by solving the pre-trianing objective
At the input side, add additional tokens based on the type of downstream task. For example, start \(\langle s \rangle\) and end \(\langle e \rangle\) tokens for classification tasks
At the output side, replace the pre-training LM head with the classification head (a linear layer \(W_y\))
Fine-tuning involves adapting a model for various downstream tasks (with a minimal or no change in the architecture)
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 12
Embedding Matrix
Now our objective is to predict the label of the input sequence
Note that we take the output representation at the last time step of the last layer \(h_l^m\).
It makes sense as the entire sentence is encoded only at the last time step due to causal masking.
Then we can minimize the following objective
Note that \(W_y\) is randomly intialized. Padding or truncation is applied if the length of input sequence is less or greater than the context length
Fine-tuning for Text Classfication
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 12
Embedding Matrix
We can freeze the pre-trained model parameters and randomly initialize the weights of the classification head (\(W_y\)) while training the model
In this case, the pre-trained model acts as a feature extractor and the classification head act as a simple classifier.
Fine-tuning for Text Classfication
The other option is to train all the parameters of the model which is called full fine-tuning
In general, the latter approach provides better performance on downstream tasks than the former.
However, there is a catch.





Fruit Fly
Honey Bee
Mouse
Cat
Brain
# Synapses
GPT-2 Small
We have trained GPT-2 small that has about 124 million parameters
It requires at least 3 to 4 GB of GPU memory to train the model with a batch of size 1 (assuming 4 bytes per parameter and adam optimizer)


(T4 has 16 GB of Memory)
Fruit Fly
Honey Bee
Mouse
Cat
Brain
# Synapses
GPT-2 Small
What about the memory required to fine-tune GPT-2 Extra Large?
It requires at least 22 to 24 GB of GPU memory to train the model with a batch of size 1 (assuming 4 bytes per parameter and adam optimizer)
(V100 has 32 GB of Memory)
GPT-2 Extra Large
Fruit Fly
Honey Bee
Mouse
Cat
Brain
# Synapses
GPT-2
Megatron LM
GPT-3
GPT-2 Small
Llama-3.2
What about the memory required to fine-tune huge models?


A single node with multiple GPUs for models having a few Billion parameters
Multi node GPU clusters for models having Billions of parameters
Fruit Fly
Honey Bee
Mouse
Cat
Brain
# Synapses
GPT-2
GPT-3
GPT-2 Small
Llama-3.2
Suppose that we have a single V100 GPU
Llama-3.2 light
Can we at least fine-tune a 3B parameters model which requires about 48 GB of Memory?
Is gradient-based fine-tuning the only approach?
If yes, what if we do not have enough samples for supervised fine-tuning?
(V100 has 32 GB of Memory)
How do we finetune the model for text interactions (like chatbot)?
Can we at least fine-tune 3B parameters models which require about 48 GB of Memory?
Many approaches have been developed to tackle the memory requirement to fine-tune large models.
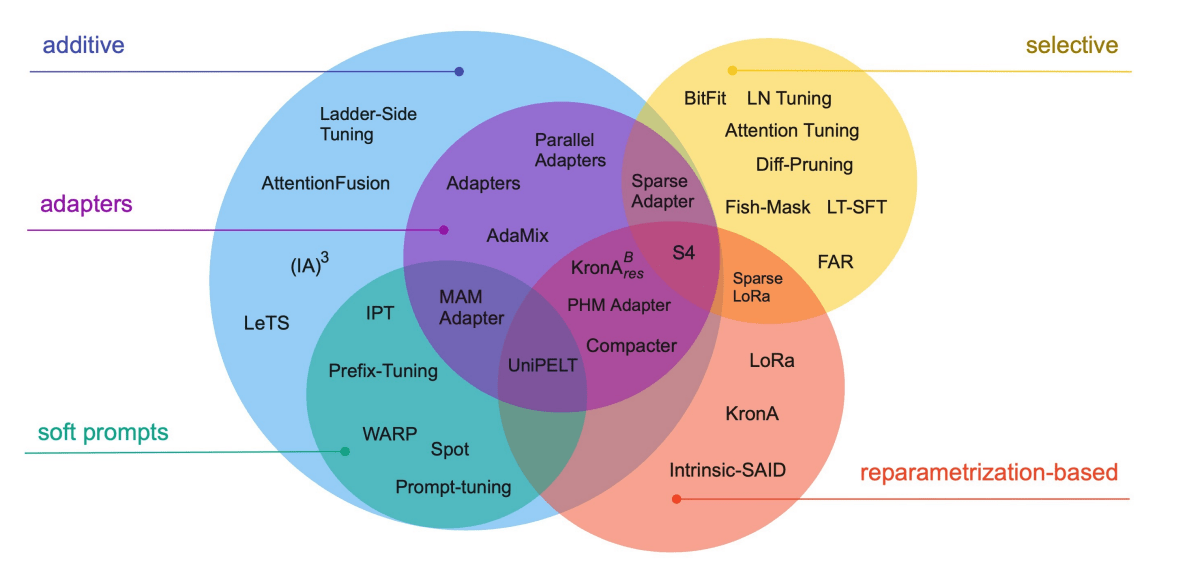
Of these Parameter Efficient Fine Tuning (PEFT) techniques, LoRa, QLoRa and AdaLoRa are most commonly used (optionally, in combination with quantization)
Emerging Abilities
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 12
Embedding Matrix
Fine-tuning large models is costly, as it still requires thousands of samples to perform well in a downstream task [Ref].
Moreover, this is not how humans adapt to different tasks once they understand the language.
We can give them a book to read and "prompt" them to summarize it or find an answer for a specific question.
That is, we do not need "supervised fine-tuning" at all (for most of the tasks)
In a nutshell, we want a single model that learns to do multiple tasks with zero or few examples (instead of thousands)!
Some tasks may not have enough labelled samples
Can we adapt a pre-trained language model for downstream tasks without any explicit supervision (called zero-shot transfer)?
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 12
Embedding Matrix
Note that, the prompts (or instructions) are words. Therefore,we just need to change the single task (LM) formulation
to multi task
where the task is just an instruction in plain words that is prepended (appended) to the input sequence during inference
Yes, with a simple tweak to the input text!
Surprisingly, this induces a model to output a task specific response for the same input
For example,
Input text: I enjoyed watching the movie transformer along with my .....
Task: summarize (or TL;DR:)
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 12
Embedding Matrix
summarize: ip text
Watched the transformer movie
To get a good performance, we need to scale up both the model size and the data size
Transformer Block 1
Transformer Block 2
Transformer Block 12
Embedding Matrix
GPT with 110 Million Parameters
GPT-2 with 1.5 Billion Parameters
Layers: \(4X\)
Parameters: \(10X\)
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 48
Embedding Matrix
Pushing the limits: 1.5B to 175B
The ability to learn from a few examples improves as model size increases
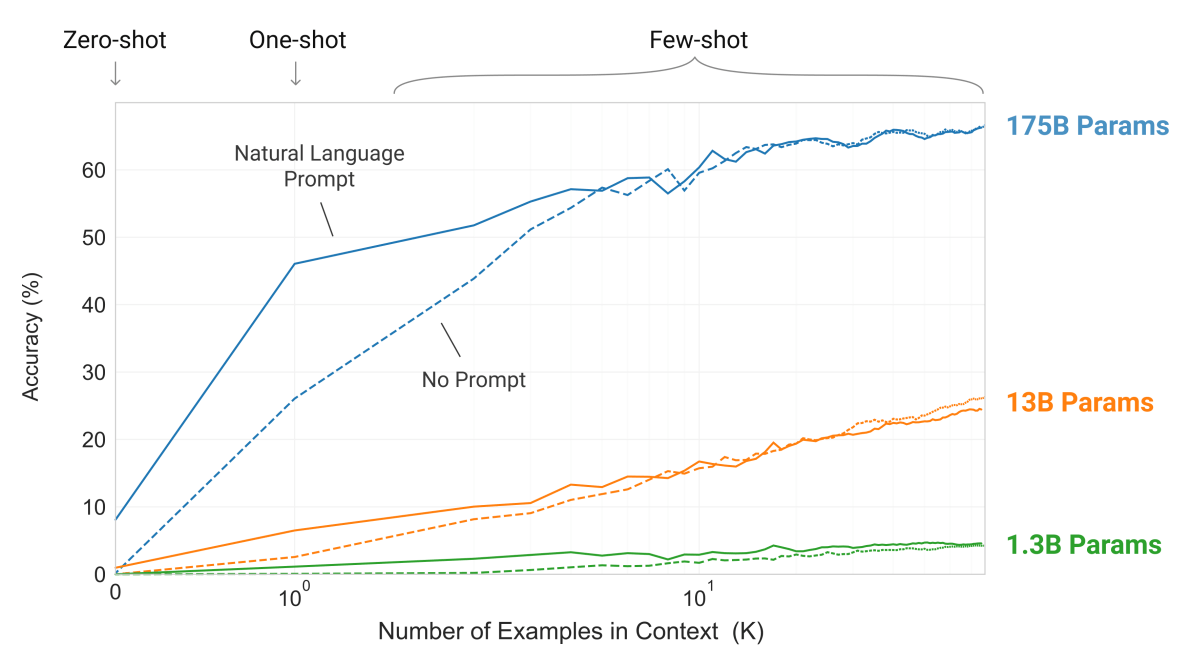
For certain tasks, the performance is comparable to that achieved through full task-specific fine-tuning.
Since the model learns a new task from samples within the context window, this approach is called 'in-context' learning.
This remarkable ability enables the adaptation of the model to downstream tasks without the need for gradient-based fine-tuning.
Adaptation happens on-the-fly in inference mode (which consumes far less memory)
Prompting
This new ability paved the way for fine-tuning the model for specific tasks by Prompting
There are many ways of prompting the model. For example,
However, there is a catch
-
Zero-shot
-
Few-shot (in-context)
-
Chain of Thought
-
Prompt Chaining
Since adaptation occurs during inference, there is no need to share model weights for fine-tuning.
This approach enables the model's deployment across a variety of use cases through simple API calls (making it more accessible)
guide the user to reach the destination
Text:how to reach Marina Beach from IIT Madrasby trainClassify the text into neutral, negative or positive. Text: I enjoyed watching the transformers movie. Sentiment:
positive
The model is unable to follow the user's intent and instead just completes the text coherently
Instruction Tuning
Zero-shot learning performance is often poor, despite the model size (say, GPT 3 175B), especially in following the user intent (instructions).
Refer to the FLAN paper for more details
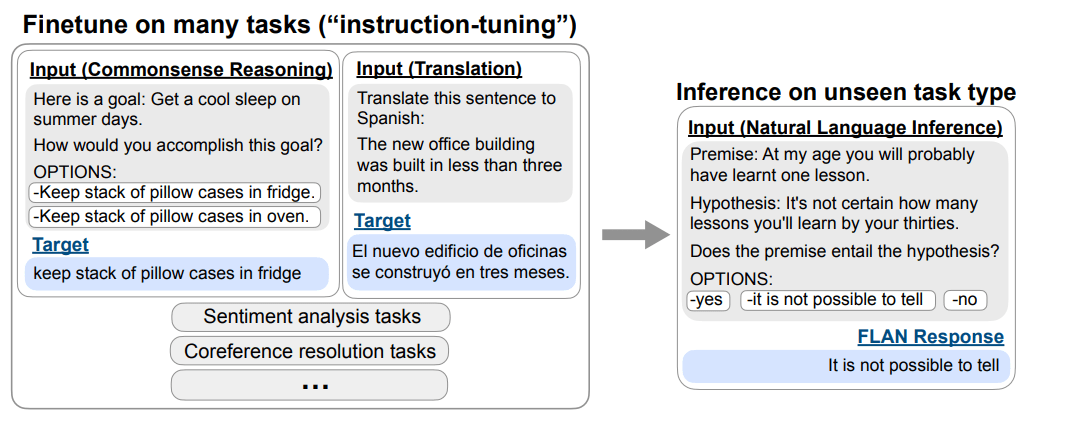
How do we improve the zero-shot learning performance?
Fine-tune the model on the instructions (one approach is to reformat the available datasets into instruction sets)
Preference Tuning via RLHF
"Making language models bigger does not inherently make them better at following a user’s intent." -[Instruct GPT paper]
This requires human labelled demonstrations for a collection of prompts (a labour intensive task)

Language Modelling objective is "misaligned" with user intent
Therefore, we must fine-tune the model to align with the user intent.
Use these collections to fine-tune (Supervised Fine Tuning , SFT ) the model using Reinforcement Leanring from Human Feedback (RLHF)


Preference Tuning via RLHF
An imagined example
Text: Guide me on how to reach Marina Beach from IIT Madras
GPT
by train
Text: Guide me on how to reach Marina Beach from IIT Madras
Instruct GPT

*Actual response from ChatGPT
Fruit Fly
Honey Bee
Mouse
Cat
Brain
# Synapses
GPT-2
GPT-3
GPT-2 Small
Llama-3.2
Suppose that we have a single V100 GPU
Llama-3.2 light
Can we at least fine-tune 3B parameters models which require about 48 GB of Memory?
Is gradient-based fine-tuning the only approach?
If yes, what if we do not have enough samples for supervised fine-tuning?
(V100 has 32 GB of Memory)
How do we finetune the model for text interactions (like chatbot)?
Yes
Prompting
No. Prompting works during inference
Instruction tuning and preference tuning (DPO,RLHF,IPO,..)
Fine-tuning
Supervised Fine-tuning (SFT)
(task agnostic) Instruction-tuning
Task-specific Full Fine-tuning
1. PEFT (Parameter Efficient Fine-tuning): LoRA, QLoRA, AdaLora
Prompt tuning
Zero-shot,
Memory efficient fine-tuning*
few-shot
Chain of Thought
Prompt chaining
Meta prompting
2. Quantization
Now we try grouping the approaches broadly into two categories
Preference Tuning: RLHF, DPO, IPO, KTO..
*general techniques to reduce memory requirement, suitable for any fine-tuning schemes
Dataset
Initialize Model
Tokenizer
from datasets import load_datasetfrom transformers import AutoTokenizerDataLoader
The list of modules we used so far

Train the model
from transformers import DataCollatorForLanguageModelingfrom transformers import GPT2Config, GPT2LMHeadModelfrom transformers import TrainingArguments, TrainerDataset
Initialize Model with pre-trained weights
Tokenizer
DataLoader
Finetune the model
from transformers import GPT2ForSequenceClassification
model = GPT2ForSequenceClassification.from_pretrained()from transformers import TrainingArguments, Trainer
from peft import LoraConfigLet's dive in
Additional Modules:
-
peft,
-
trl,SFTTrainer (for preference tuning)
-
bitsandbytes (quantization)
-
Unsloth (for single-gpu, 2.5x faster training)
Notebooks: Github Link

Experimental Setup
Outline
Supervised Fine Tuning
Continual PreTraining
Instruction Fine Tuning
How does LLM generate a factual answer for a question?
How does LLM generate a factual answer for a question?
InstructGPT
RAG
Agent
Indexing
Get the learned embedding