Deep Learning Practice - NLP
Language Modelling, GPT, Pretraining using
HF Transformers
Mitesh M. Khapra, Arun Prakash A


AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Dataset
So far
import datasetsimport transformersimport evalauteWe have learned how to load any dataset from the HF hub, access samples, modify them and save them back using HF datasets module.
We learned how to load any dataset from the HF hub, access and modify samples, and save them to disk using the HF datasets module.



So far
Dataset
Encode Text
Initialize
Model
Decode Predictions


Tokenizer
import datasetsimport tokenizerstokenizer.encode()tokenizer.decode()Next, we learned how to train a tokenizer that encodes input text according to the model-specific template and decodes the model's predictions
In this week
Dataset
Encode Text
Initialize
Model
Train the model
Decode Predictions

Tokenizer
import datasetsimport tokenizerstokenizer.encode()tokenizer.decode()import transformerswe will learn how to train transformer based models using the HF transformers module.
BookCorpus
Wikipedia
OpenWebText
RealNews
C4, The Pile
ROOTS
The size of datasets has kept growing
Over the Years





Fruit Fly
Honey Bee
Mouse
Cat
Brain
# Synapses
Transformer
GPT-2
Megatron LM
GPT-3
Here is the Evolution tree

We can group the transformer based models into three categories
Encoder-only models (BERT and its variants) dominated the field for about two years
Decoder-only models (GPT) soon emerged for the task of Language modeling
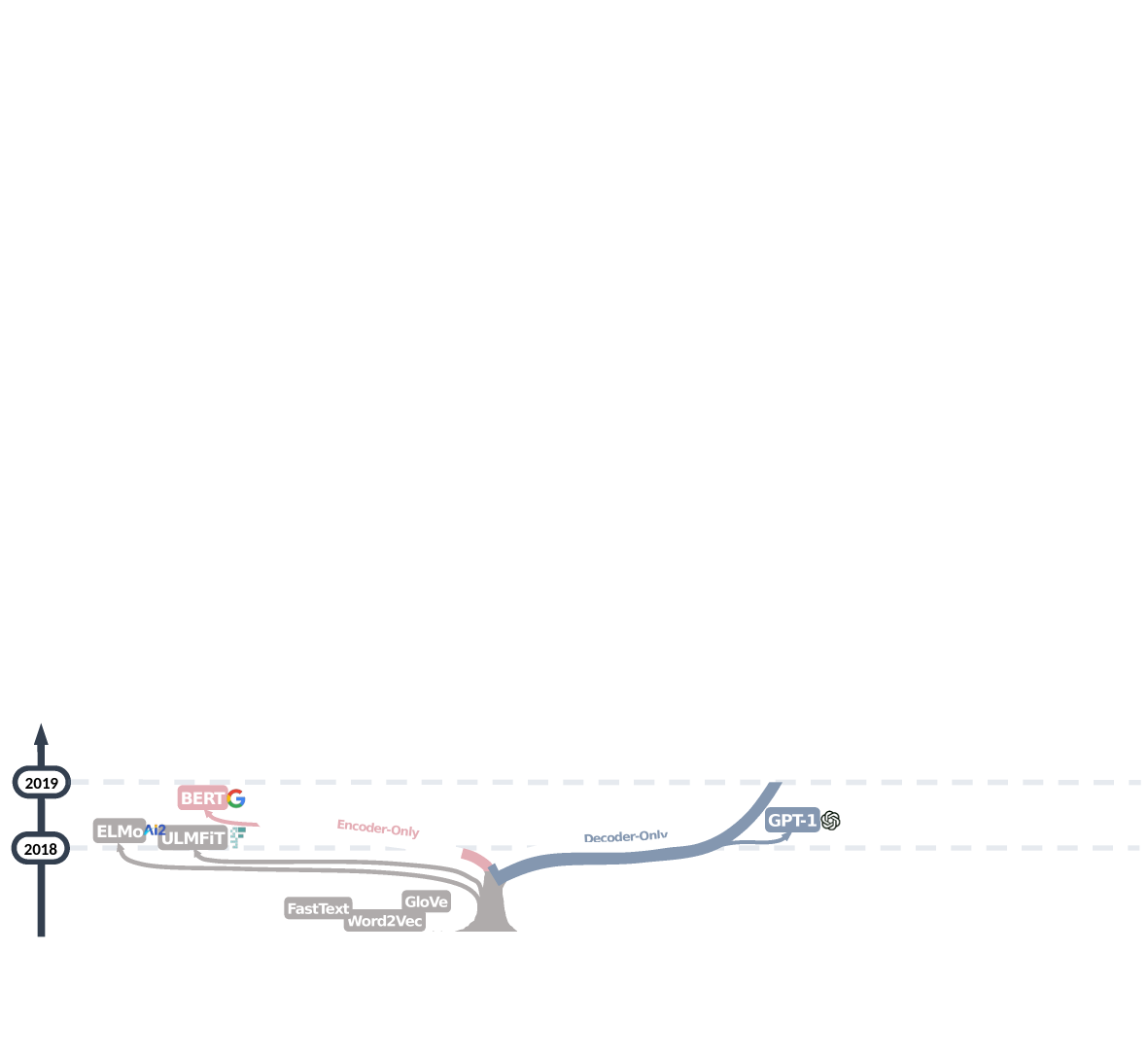

Encoder-only models (BERT and its variants) dominated the field for about two years
GPT-2 and T5 advocated for decoder only models and encoder-decoder models, respectively.
Model
Dataset
-
Scale the model or dataset or both?
-
What is the proportion of scaling?
The tree has grown bigger

The tree has grown bigger and bigger


The tree has grown bigger and bigger in a short span of time

Even if we select only the decoder branch in the evaluation tree
there would still be dozens of models
However, all of these LLMs go through a phase called pretraining.
Let’s try to understand this using the GPT (Generative Pretrained Transformer) model.
In the DL course, we learned about the components of the transformer architecture in the context of machine translation.
At a higher level of abstraction, we can view it as a black box that takes an input and generates an output.
Transformer
Text in source language
Translated text in target language
In the DL course, we learned about the components of the transformer architecture in the context of machine translation.
Transformer
Transformer
Transformer
Input text
Predict the class/sentiment
Input text
Summarize
Question
Answer
Input text
What if we want to use the transformer architecture for other NLP tasks?
We need to train a separate model for each task using a dataset specific to the task
In the DL course, we learned about the components of the transformer architecture in the context of machine translation.
Transformer
Transformer
Transformer
Input text
Predict the class/sentiment
Input text
Summarize
Question
Answer
Input text
What if we want to use the transformer architecture for other NLP tasks?
We need to train a separate model for each task using dataset specific to the task
If we train the architecture from scratch (that is, by randomly initializing the parameters) for each task, it takes a long time for convergence
Often, we may not have enough labelled samples for many NLP tasks
Moreover, preparing labelled data is laborious and costly
On the other hand,
we have a large amount of unlabelled text easily available on the internet
Transformer
Transformer
Transformer
Input text
Predict the class/sentiment
Input text
Summarize
Question
Answer
Input text

Can we make use of such unlabelled data to train a model?
Module 3.1 : Language Modelling
Mitesh M. Khapra
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Motivation
" Wow, India has now reached the moon"
Is this sentence expressing a positive or a negative sentiment?
An excerpt from business today "What sets this mission apart is the pivotal role of artificial intelligence (AI) in guiding the spacecraft during its critical descent to the moon's surface."
Did the lander use AI for soft landing on the moon?
Assume that we ask questions to a lay person based on a statement or some excerpt
He likes to stay
He likes to stray
He likes to sway
Are these meaningful sentences?
The person will most likely answer all the questions, even though he/she may not be explicitly trained on any of these tasks. How?
We develop a strong understanding of language through various language based interactions( listening/reading) over our life time without any explicit supervision

Can a model develop basic understanding of language by getting exposure to a large amount of raw text? [pre-training]
More importantly, after getting exposed to such raw data can it learn to perform well on downstream tasks with minimum supervision? [Supervised Fine-tuning]
Idea

With this representation a linear model classifies reviews with 91.8% accuracy beating the SOTA (Ref)
...matches the performance of previous supervised systems using 30-100x fewer labeled examples (Ref)
Language Modeling
(Pre-training)

Raw text
Downstream tasks
(Fine-tuning)
(Samples and labels)

Language modelling
Let \(\mathcal{V}\) be a vocabulary of language (i.e., collection of all unique words in the language)
For example, if \(\mathcal{V}=\{an, apple, ate, I\}\), some possible sentences (not necessarily grammatically correct) are
Intuitively, some of these sentences are more probable than others.
We can think of a sentence as a sequence \(X_1,X_2, \cdots,X_n\), where \(X_i \in \mathcal{V}\)
a. An apple ate I
b. I ate an apple
c. I ate apple
d. an apple
e. ....
What do we mean by that?
Intuitively, we mean that give a very very large corpus, we expect some of these sentences to appear more frequently than others (hence, more probable)
We are now looking for a function which takes a sequence as input and assigns a probability to each sequence
Such a function is called a language model.
Language modelling
Definition
If we naively assume that the words in a sequence are independent of each other then
How do we enable a model to understand language?

Simple Idea: Teach it the task of predicting the next token in a sequence..
You have tons of sequences available on the web which you can use as training data
Roughly speaking, this task of predicting the next token in a sequence is called language modelling

?


However, we know that the words in a sentence are not independent but depend on the previous words
a. I enjoyed reading a book
b. I enjoyed reading a thermometer
The presence of "enjoyed" makes the word "book" more likely than "thermometer"
Hence, the naive assumption does not make sense
Current word \(\underbrace{x_i} \) depends on previous words \(\underbrace{x_1,\cdots,x_{i-1}} \)
Current word \(\underbrace{x_i} \) depends on previous words \(\underbrace{x_1,\cdots,x_{i-1}} \)
How do we estimate these conditional probabilities?
One solution: use autoregressive models where the conditional probabilities are given by parameterized functions with a fixed number of parameters (like transformers).
Causal Language Modelling (CLM)
We are looking for \(f_{\theta}\) such that
Can \(f_{\theta}\) be a transformer?
Transformer
\(x_1,x_2,\cdots,x_{i-1}\)

\(P(x_i)\)
Using only the encoder of the transformer (encoder only models)
Using only the decoder of the transformer (decoder only models)
Using both the encoder and decoder of the transformer (encoder decoder models)
Multi-Head Attention
Feed forward NN
Add&Norm
Add&Norm
\(x_1,<mask>,\cdots,x_{T}\)
\(P(<mask>)\)
Multi-Head masked Attention
Feed forward NN
Add&Norm
Add&Norm
\(x_1,x_2,\cdots,x_{i-1}\)
\(P(x_i)\)
Multi-Head Attention
Feed forward NN
Add&Norm
Add&Norm
Multi-Head cross Attention
Feed forward NN
Add&Norm
Add&Norm
Multi-Head Maksed Attention
Add&Norm
\(x_1,<mask>,\cdots,x_{T}\)
\(<go>\)
\(P(<mask>)\)
Some Possibilities
Feed Forward Network
Masked Multi-Head (Self)Attention
Multi-Head (Cross) Attention
The input is a sequence of words
We want the model to see only the present and past inputs.
We can achieve this by applying the mask.
The masked multi-head attention layer is required.
However, we do not need multi-head cross attention layer (as there is no encoder).
Feed Forward Network
Masked Multi-Head (Self)Attention
The outputs represent each term in the chain rule
However, this time the probabilities are determined by the parameters of the model,
Therefore, the objective is to maximize the likelihood \(L(\theta)\)
Module 3.2 : Generative Pretrained Transformer (GPT)
Mitesh M. Khapra
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Generative Pretrained Transformer (GPT)
Now we can create a stack \((n)\) of modified decoder layers (called transformer block in the paper)
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 4
Transformer Block 5
Let, \(X\) denote the input sequence
Where \(h_n[i]\) is the \(i-\)the output vector in \(h_n\) block.
Input data

BookCorpus
The corpus contains 7000 unique books, 74 Million sentences and approximately 1 Billion words across 16 genres
Also, uses long-range contiguous text
(i.e., no shuffling of sentences or paragraphs)
Side Note: The other benchmark dataset called 1B words could also be used. However, the sentences are not contiguous (no entailment)
Vocab size \(|\mathcal{V}|\): 40478
Tokenizer: Byte Pair Encoding
Embedding dim: \(768 \)
MODEL
Contains 12 decoder layers (transformer blocks)
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 12
FFN hidden layer size: \(768 \times 4 = 3072\)
Attention heads: \(12 \)
Context size: \(512 \)
Dropout, layer normalization, and residual connections were implemented to enhance convergence during training.
Activation: Gaussian Error Linear Unit (GELU)

Transformer Block 1
<go>
at
the
bell
labs
hamming
bound
...................
new
a
devising
..............
<stop>
A sample data
Transformer Block 1
<go>
at
the
bell
labs
hamming
bound
...................
new
a
devising
..............
<stop>
Feed Forward Neural Network
Multi-head masked attention
<go>
at
the
bell
labs
hamming
bound
...................
new
a
devising
..............
<stop>
Masked Multi-head attention
Concatenate
Linear
Layer norm
Residual connection
<go>
at
the
bell
labs
hamming
bound
...................
new
a
devising
..............
<stop>
Masked Multi-head attention
Feed Forward Neural Network


Layer norm
Residual connection
Number of parameters
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 12
token Embeddings: \(|\mathcal{V}| \times \) embedding_dim
Position Embeddings : context length \(\times\) embedding_dim
Embedding Matrix
Total: \(31.3 M\)
The positional embeddings are also learned, unlike the original transformer which uses fixed sinusoidal embeddings to encode the positions.
Number of parameters
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 12
Attention parameters per block
Per attention head
For 12 heads
For a Linear layer:
For all 12 blocks
Number of parameters
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 12
FFN parameters per block
For all 12 blocks
Number of parameters
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 12
| Layer | Parameters (in Millions) |
|---|---|
| Embedding Layer | |
| Attention layers | |
| FFN Layers | |
| Total |
Embedding Matrix
*Without rounding the number of parameters in each layer
Thus, GPT-1 has around 117 million parameters.
Module 3.3 : HF Transformers
Mitesh M. Khapra
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
In this week
Dataset
Encode Text
Initialize
Model
Train the model
Decode Predictions
Tokenizer
import datasetsimport tokenizerstokenizer.encode()tokenizer.decode()import transformerswe will learn how to train transformer based models using the HF "transformers" module.
Recall that we can create any architecture with a few lines of code in PyTorch
class TRANSFORMER(torch.nn.Module):
def __init__(self,vocab_size,embed_dim,hidden_dim,num_class):
super().__init__()
self.embedding = nn.Embedding(vocab_size,
embed_dim,
padding_idx=0)
self.transformer = nn.Transformer(dmodel,
nhead,
num_encoder_layers,
num_decoder_layers,
dim_feedforward)
self.fc = Linear(dmodel, vocab_size)
def forward(self, x,length)
x = self.embedding(x)
x = self.transformer(x)
x = self.fc(x[1])
return xclass RNN(torch.nn.Module):
def __init__(self,vocab_size,embed_dim,hidden_dim,num_class):
super().__init__()
self.embedding = nn.Embedding(vocab_size,
embed_dim,
padding_idx=0)
self.rnn = nn.RNN(embed_dim,
hidden_dim,
batch_first=True)
self.fc = nn.Linear(hidden_dim, num_class)
def forward(self, x,length)
x = self.embedding(x)
x = pack_padded_sequence(x,
lengths=length,
enforce_sorted=False,
batch_first=True)
x = self.rnn(x)
x = self.fc(x[1])
return xclass CNN(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 10)
self.fc2 = nn.Linear(10, 4)
self.fc3 = nn.Linear(4, 2)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return xWe can also set up the entire training pipeline in PyTorch
HF with PyTorch Backend
| 1 |
|---|
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
| 10 |
| 11 |
| 12 |
| 13 |
| 14 |
| 15 |
| 16 |
| 17 |
| 18 |
N samples
in a storage



torch.tensor
Torch.nn.module
(Linear, Transformer)
torch.optim

.Step
Training any deep learning model in PyTorch follows the sequence of operations as shown above.
torch.nn.Parameter
torch.autograd
How do we fetch the data for training the model ?
We can slice the batch and iterate, not a big deal! wait..

HF transformers module further abstracts this sequence of operations
| 1 |
|---|
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
| 10 |
| 11 |
| 12 |
| 13 |
| 14 |
| 15 |
| 16 |
| 17 |
| 18 |
N samples
in a storage
| 1 |
|---|
| 10 |
| 5 |
| 4 |
| 3 |
| 6 |
| 17 |
| 8 |
| 9 |
| 2 |
| 11 |
| 16 |
| 13 |
| 14 |
| 15 |
| 12 |
| 7 |
| 18 |
Shuffled indices

Model Under
training
Fetching the next set of batches simultaneously when the model is being trained is not possible due to python's GIL (Global Interpreter Lock)
Fetch
(Model waits until samples are fetched)
Samples may need to be randomly shuffled
The complexity of distributing data to multiple GPUs in distributed training is high.
Therefore we need a mechanism that efficiently handles all these requirements
The complexity becomes even greater in a multinode distributed training setup
Dataset
Encode
Text
Initialize
Model
Train the model
Tokenizer
import datasetsimport tokenizerstokenizer.encode()import transformersCurrent Training Setup
Dataset
Encode
Text
Initialize
Model
Train the model
Tokenizer
import datasetsimport tokenizerstokenizer.encode()import transformersDataLoader
Training with DataLoader

Dataset
Initialize Model
Tokenizer
from datasets import load_datasetfrom transformers import AutoTokenizerDataLoader
The Main Sections of the Hands-on Notebook
Train the model
from transformers import DataCollatorForLanguageModelingfrom transformers import GPT2Config, GPT2LMHeadModelfrom transformers import TrainingArguments, TrainerLet's dive in
HF with PyTorch Backend
| 1 |
|---|
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
| 10 |
| 11 |
| 12 |
| 13 |
| 14 |
| 15 |
| 16 |
| 17 |
| 18 |
torch.tensor
Torch.nn.module
(Linear, Transformer)
torch.optim
.Step
torch.nn.Parameter
torch.autograd