PCA-Kernel PCA
Arun Prakash A
Steps

Center the datapoints. Why?
\(n\): # of samples, \(d\): # of features

Compute the covariance of ___?
(Different from lecture)
Compute the covariance of features
What is the sample variance for the features \(f_1,f_2\) (given that mean is zero)?
for \(n\) samples,
That is, simply square the elements of first column and sum them up
Repeat the same to compute the variance for all features
What is the sample co-variance between the features \(f_1,f_2\) (given that mean is zero)?
Variance of feature 1
Variance of feature 2
What does \(var(x)=1.6\) compared to \(var(x)=0.4\) , mean?
Roughly, the data spread along \(x-axis\) two times more than along \(y-axis\) (in the canonical bases)
What does \(var(x)=1.6\) compared to \(var(x)=0.4\) , mean?
Roughly, the datapoints spread along \(x-axis\) two times more than along \(y-axis\) (in the canonical bases)
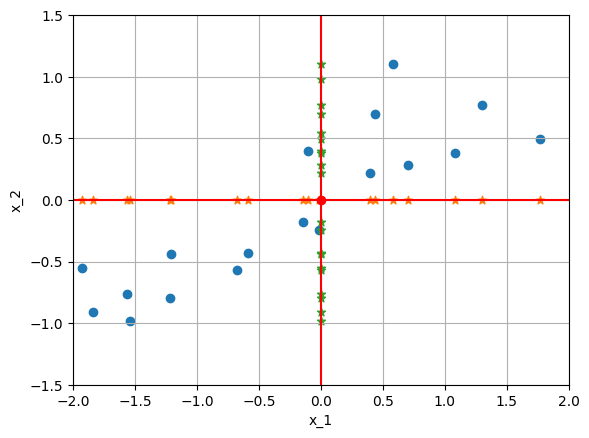
Moreover, the diagonal elements say that \(x\) and \(y\) are positively correlated.
We want to decorrelate the features and maximize the variance in a particular direction (say \(x\))
We look for other bases (direction)?

Rotate data points by \(Q\)

Features are decorrelated!
Eigen vectors are the principal directions
The coordinate (eigenvalue) of the Eigen vectors are the principal components
Dual Formulation
Is this a covariance matrix ?
No. Why?
For it to be a variance
However, we have
Sum square of all the features in the first sample
Sum square of the first feature in all the samples
But \(K\) is a Symmteric Matrix!
For example
Is there a relation ship between eigen vectors of \(K\) and \(C\)?
Is there a relation ship between eigenvalues of \(K\) and \(C\)?
Eigenvector of \(C\):
What is the size of the eigenvector?
Eigenvector of \(K\):
What is the size of the eigenvector?
We might need a transformation matrix that maps these eigenvectors!
Let's Jump in!
,Let \(w_k\) be the \(k-th\) eigen vector of \(C\)
\(w_k\) is a linear combination of all data points
Multiply both sides by \(X\)
Therefore, \(\alpha_k\) is the eigen vector of \(K\)
How do we find the \(\alpha_k\)?
Substitute
in
Imposing unit norm condition: \(w_k^Tw_k\)=1
Replace \(K\alpha_k\) by
Algorithm
Compute \(K=XX^T \in \mathbb{R}^{n \times n}\)
FInd the eigenvalues (\(n\lambda_1,n\lambda_2,\cdots,n\lambda_n\)) and eigenvectors (\(\alpha_1,\alpha_2,\cdots,\alpha_n\))
Scale down the eigenvectors (\(\alpha_1,\alpha_2,\cdots,\alpha_n\)) by square root of its eigenvalues.
Transform the scaled down eigenvectors by \(X^T\)
The eigenvalues are non-negative as \(C\) is positive semi-definite.
The eigenvalues are non-negative as \(K\) is a Gram-Matrix which is positive semi-definite.
Important Observation
Each element in \(C\) is coming out of inner-product of elements from the set \(X\)
Each element in \(K\) is coming out of inner-product of elements from the set \(X\)
Albeit, in different ways
So both matrices are Gram Matrix!
We can move back and forth between these formulations using the set \(X\) !
Non-Linear Relationships
Dot product
Assuming \(x,y\) are normalized
Gives angle
Scalar projection
Length of a vector

Interpretation-1: Similarity
Similar in \(\mathbb{R}^{10}\) ( equals 1 if the vector is normalized)
Zero similarity in \(\mathbb{R}^{10}\)
Any better similarity measure?
Motivation


Ok. Polynomial transformation separates these data points
Suppose we want to project these onto a place. Where should we project?
On to the \(uv\) plane?
Motivation
On to \(uv\) plane?

Motivation
Datapoints in inputspace \(X\)
Datapoints in Feature space \(\Phi(X)\)
Projection in the Feature space \(\Phi(X)^T(?)\)
Replace ? with the Equation of the plane




Source:BernhardNow your turn to make sense of these pictures
Each element in the covariance matrix is a dot product between a row of \(X\) and a column of \(X^T\).
Relation
What does this dot product say?
Note the vector \(u\) is fixed given \(a,b,r\)
We transform each data point using \(\Phi\).
Then,
What does this dot product say?
Note the vector \(u\) is fixed.
Possible directions of \(\Phi\)?

All the transformed datapoints now lie on a linear sub-space spanned by two independent vectors!
Note, however, that we do not know the distribution of the points in the transformed space. We only know that it is sitting in the linear subspace.
Objective: Find the principal components in the transformed subspace
num of samples
num of features in \(\mathcal{X}\)
num of features in \(\mathbb{H}\)
use \(C=X^TX\)
use \(K=XX^T\)
Given that feature space could easily reach \(10^{10}\) dimension (or infinite)

\(p\)-th order polynomial
requires \(d^2\) dot products
requires \(n^2\) dot products
\(C_{\Phi}=\Phi(X)^T \Phi(X)\)
requires \(D^2\) dot products
\(K_{\Phi}=\Phi(X) \Phi(X)^T\)
requires \(n^2\) dot products
Computing \(\Phi(x)\) in itself is infeasible!
Lower dimensional input space
Higher (including infinite) dimensional Feature space (aka,Hilbert Space)
The computation in \(\mathcal{X}\) that induces inner prodcut in \(\mathbb{H}\)
In practice, dim of \(10^{10},10^{15}\) could easily occur
A Kernel function does that
Carrying out inner product is costly. Say, we need \(10^{10}\) multiplications and additions to compute single dot product
Polynomial Kernel
Is equal to transforming the data point by
and computing the inner product
Therefore, the \(ij-th\) element of covariance matrix in the feature space is given by \(ij-th\) element of \(K\):
Computational complexity: Polynomial transformation of degree 10
[We do not directly compute this]
We are now facing a problem.
How do we compute
We do not have \(x_7\)? or any of \(x_i, i>6\).
What could be the solution?
Computational complexity: Polynomial transformation of degree 10
[We do not directly compute this]
Interesting part is here,
We have already computed this in \(K\)
Use this:
We already know how to move from \(K\) to \(C\)
Computational complexity: Polynomial transformation of degree 10
[We do not directly compute this]
The dataset \(X_\Phi\) is not centered.
We can center it by computing mean of \(X_\Phi\). However, we can not, because...?
Therefore, center the Kernel
Compute eigenvector \(w_k^\Phi\) using
Once again we never compute \(X_\Phi\)
Why do we need eigenvectors if all that we need is compression?
Projection of the transformed point on to the k-th eigenvector of \(K_\Phi\)
Can any function
be a kernel?
The transformation has to be a real inner product
Linear
Guassian/radial
Exponential, laplacian
sigmoidal
All Polynomial transformation
Summary
kth eigen-value and eigenvector is
Summary
kth eigen-value and eigenvector is
Transform the scaled down eigenvectors by \(X^T\)
num of samples
num of features in \(\mathcal{X}\)
num of features in \(\mathbb{H}\)
use \(C=X^TX\)
use \(K=XX^T\)
Given that feature space could easily reach \(10^{10}\) dimension (or infinite)
\(p\)-th order polynomial
requires \(d^2\) dot products
requires \(n^2\) dot products
\(C_{\Phi}=\Phi(X)^T \Phi(X)\)
requires \(D^2\) dot products
\(K_{\Phi}=\Phi(X) \Phi(X)^T\)
requires \(n^2\) dot products
Computing \(\Phi(x)\) in itself is infeasible!
Computational complexity: Polynomial transformation of degree 10
[We do not directly compute this]
Interesting part is here,
We have already computed this in \(K\)
Use this:
We already know how to move from \(K\) to \(C\)
Computational complexity: Polynomial transformation of degree 10
[We do not directly compute this]
The dataset \(X_\Phi\) is not centered.
We can center it by computing mean of \(X_\Phi\). However, we can not, because...?
Therefore, center the Kernel
Compute eigenvector \(w_k^\Phi\) using
Once again we never compute \(X_\Phi\)