CS6910: Fundamentals of Deep Learning
Lecture 1: (Partial/Brief) History of Deep Learning
Mitesh M. Khapra, Arun Prakash A


AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Acknowledgements
Most of the early material is based on the article “Deep Learning in Neural Networks: An Overview" by J. Schmidhuber
The errors, if any, are due to me and I apologize for them
Feel free to contact me if you think certain portions need to be corrected (please provide appropriate references)
|
|
|---|
Chapter 1: Biological Neurons
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Mitesh M. Khapra, Arun Prakash A
Reticular Theory


1871-1873
Reticular theory
Joseph von Gerlach proposed that the nervous system is a single continuous network as opposed to a network of many discrete cells!
Staining Technique
1871-1873
Reticular theory
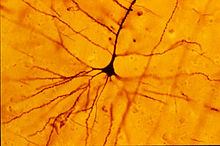
Camillo Golgi discovered a chemical reaction that allowed him to examine nervous tissue in much greater detail than ever before
He was a proponent of Reticular theory
Neuron Doctrine
1871-1873
Reticular theory
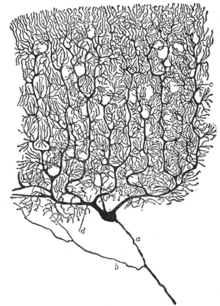
Santiago Ramón y Cajal used Golgi’s technique to study the nervous system and proposed that it is actually made up of discrete individual cells formimg a network (as opposed to a single continuous network)
1888-1891
Neuron Doctrine
The Term Neuron
1871-1873
Reticular theory
The term neuron was coined by Heinrich Wilhelm Gottfried von Waldeyer-Hartz around 1891.
1888-1891
Neuron Doctrine
He further consolidated the Neuron Doctrine.

Nobel Prize
1871-1873
Reticular theory
Both Golgi (reticular theory) and Cajal (neuron doctrine) were jointly awarded the 1906 Nobel Prize for Physiology or Medicine, that resulted in lasting conflicting ideas and controversies between the two scientists.
1888-1891
Neuron Doctrine

1906
Nobel Prize
The Final Word
1871-1873
Reticular theory
In 1950s electron microscopy finally confirmed the neuron doctrine by unambiguously demonstrating that nerve cells were individual cells interconnected through synapses (a network of many individual neurons).
1888-1891
Neuron Doctrine
1906
Nobel Prize

1950
Synapse
The great brain debate
Chapter 2: From Spring to Winter of AI
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Mitesh M. Khapra, Arun Prakash A
McCulloch Pitts Neuron
McCulloch (neuroscientist) and Pitts (logician) proposed a highly simplified model of the neuron (1943).
1943
MPNeuron
\(f\)
\(g\)
\(x_1\)
\(x_2\)
\(x_n\)
..
..
\(y\in \lbrace0,1\rbrace\)
\(\in \lbrace0,1\rbrace\)
Perceptron
“the perceptron may eventually be able to learn, make decisions, and translate languages” -Frank Rosenblatt
1943
MPNeuron
\(x_1\)
\(x_2\)
\(x_n\)
..
..
\(y\)
\(g\)
\(f\)
\(w_1\)
\(w_2\)
\(w_n\)
1957-58
Perceptron
Perceptron
“the embryo of an electronic computer that the Navy expects will be able to walk, talk, see, write, reproduce itself and be conscious of its existence.” -New York Times
1943
MPNeuron
1957-58
Perceptron

First generation Multilayer Perceptrons
1943
MPNeuron
1957-58
Perceptron
1965-1968
MLP

Perceptron Limitations
In their now famous book “Perceptrons”, Minsky and Papert outlined the limits of what perceptrons could do
1943
MPNeuron
1969
Limitations
1957-58
Perceptron
1965-1968
MLP


AI Winter of connectionism
Almost lead to the abandonment of connectionist AI
1943
MPNeuron
1969
Limitations
1986
\(\leftarrow\) AI Winter \(\rightarrow\)
1957-58
Perceptron
1965-1968
MLP

Backpropagation
Discovered and rediscovered several times throughout 1960’s and 1970’s
Werbos(1982) first used it in the context of artificial neural networks
Eventually popularized by the work of Rumelhart et. al. in 1986
1943
MPNeuron
1969
Limitations
1986
\(\leftarrow\) AI Winter \(\rightarrow\)
Backpropagation
1957-58
Perceptron
1965-1968
MLP

Gradient Descent
Cauchy discovered Gradient Descent motivated by the need to compute the orbit of heavenly bodies
1943
MPNeuron
1969
Limitations
1986
\(\leftarrow\) AI Winter \(\rightarrow\)
Backpropagation
1847
Gradient Descent
1957-58
Perceptron
1965-1968
MLP

Universal Approximation Theorem
A multilayered network of neurons with a single hidden layer can be used to approximate any continuous function to any desired precision
1943
MPNeuron
1969
Limitations
1986
\(\leftarrow\) AI Winter \(\rightarrow\)
Backpropagation
1847
Gradient Descent
1989
UAT
1957-58
Perceptron
1965-1968
MLP
Chapter 3: The Deep Revival
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Mitesh M. Khapra, Arun Prakash A
Unsupervised Pre-Training
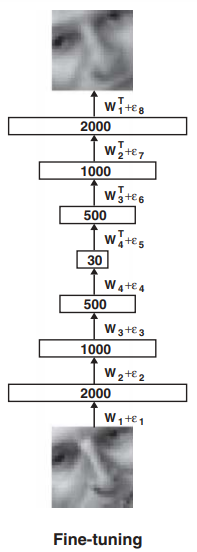
Hinton and Salakhutdinov described an effective way of initializing the weights that allows deep autoencoder networks to learn a low-dimensional representation of data.
2006
Unsupervised pre-training
Unsupervised Pre-Training
The idea of unsupervised pre-training actually dates back to 1991-1993 (J. Schmidhuber) when it was used to train a “Very Deep Learner”
2006
Unsupervised pre-training
1991-1993
Very Deep learner
More insights (2007-2009)
Further Investigations into the effectiveness of Unsupervised Pre-training

2006
Unsupervised pre-training
1991-1993
Very Deep learner
2009
Success in Handwriting Recognition
Graves et. al. outperformed all entries in an international Arabic handwriting recognition competition
2006
Unsupervised pre-training
1991-1993
Very Deep learner
2008

Handwriting
New record on MNIST
Ciresan et. al. set a new record on the MNIST dataset using good old backpropagation on GPUs (GPUs enter the scene)
2006
Unsupervised pre-training
1991-1993
Very Deep learner
2008
Handwriting
2010
MNIST

Success in Speech Recognition

2006
Unsupervised pre-training
1991-1993
Very Deep learner
2008
Handwriting
2012
Speech
2010
MNIST
First Superhuman Visual Pattern Recognition

2006
Unsupervised pre-training
1991-1993
Very Deep learner
2008
Handwriting
2012
Speech/
Traffic-sign
2010
MNIST
Winning more visual recognition challenges

| Network | Error | Layers |
|---|---|---|
| AlexNet | 16.0 % | 8 |
2006
Unsupervised pre-training
1991-1993
Very Deep learner
2008
Handwriting
2012-2016
Sucess on ImageNet
2010
MNIST
Winning more visual recognition challenges
| Network | Error | Layers |
|---|---|---|
| AlexNet | 16.0 % | 8 |
| ZFNet | 11.2% | 8 |
2006
Unsupervised pre-training
1991-1993
Very Deep learner
2008
Handwriting
2012-2016
Sucess on ImageNet
2010
MNIST
Winning more visual recognition challenges
| Network | Error | Layers |
|---|---|---|
| AlexNet | 16.0 % | 8 |
| ZFNet | 11.2% | 8 |
| VGGNet | 7.3% | 19 |
2006
Unsupervised pre-training
1991-1993
Very Deep learner
2008
Handwriting
2012-2016
Sucess on ImageNet
2010
MNIST
Winning more visual recognition challenges
| Network | Error | Layers |
|---|---|---|
| AlexNet | 16.0 % | 8 |
| ZFNet | 11.2% | 8 |
| VGGNet | 7.3% | 19 |
| GoogLeNet | 6.7% | 22 |
2006
Unsupervised pre-training
1991-1993
Very Deep learner
2008
Handwriting
2012-2016
Sucess on ImageNet
2010
MNIST
Winning more visual recognition challenges
| Network | Error | Layers |
|---|---|---|
| AlexNet | 16.0 % | 8 |
| ZFNet | 11.2% | 8 |
| VGGNet | 7.3% | 19 |
| GoogLeNet | 6.7% | 22 |
| MS ResNet | 3.6% | 152 |
2006
Unsupervised pre-training
1991-1993
Very Deep learner
2008
Handwriting
2012-2016
Sucess on ImageNet
2010
MNIST
Chapter 4: : From Cats to Convolutional Neural Networks
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Mitesh M. Khapra, Arun Prakash A
Hubel and Wiesel Experiment
Experimentally showed that each neuron has a fixed receptive field - i.e. a neuron will fire only in response to a visual stimuli in a specific region in the visual space
1959
H and W experiment

Neocognitron
1959
H and W experiment


1980
NeoCognitron

Convolutional Neural Network
1959
H and W experiment
Handwriting digit recognition using backpropagation over a Convolutional Neural Network (LeCun et. al.)
1980
NeoCognitron

CNN
1989
LeNet-5
1959
H and W experiment
1980
NeoCognitron
CNN
1989
LeNet-5
1998

An algorithm inspired by an experiment on cats is today used to detect cats in videos :-)
Chapter 5: Faster, higher, stronger
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Mitesh M. Khapra, Arun Prakash A

Better Optimization Methods

Faster convergence, better accuracies

1983
Nesterov
Better Optimization Methods
Faster convergence, better accuracies
1983
Nesterov
2011
AdaGrad

Better Optimization Methods
Faster convergence, better accuracies
1983
Nesterov
2011
AdaGrad
2012
RMSProp
Better Optimization Methods
Faster convergence, better accuracies
1983
Nesterov
2011
AdaGrad
2012
RMSProp
2015
Adam

Better Optimization Methods
Faster convergence, better accuracies
1983
Nesterov
2011
AdaGrad
2012
RMSProp
2015
Adam
2016
NAdam
Better Optimization Methods
Faster convergence, better accuracies
1983
Nesterov
2011
AdaGrad
2012
RMSProp
2015
Adam
2016
NAdam
2017
AdamW
Better Optimization Methods
Faster convergence, better accuracies
1983
Nesterov
2011
AdaGrad
2012
RMSProp
2015
Adam
2016
NAdam
2017
AdamW
2019
RAdam
Better Optimization Methods
Faster convergence, better accuracies
1983
Nesterov
2011
AdaGrad
2012
RMSProp
2015
Adam
2016
NAdam
2017
AdamW
2019
RAdam
2020
Ada-Belief

Better Optimization Methods
Faster convergence, better accuracies
1983
Nesterov
2011
AdaGrad
2012
RMSProp
2015
Adam
2016
NAdam
2017
AdamW
2019
RAdam
2020
Ada-Belief
2021
MADGRAD

Better Activation Functions
We have come a long way from the initial days when the logistic function was the default activation function in NNs!
1980-1990
Logistic Function
Over the past few years many new functions have been proposed leading to better convergence and/or performance!

Better Activation Functions
We have come a long way from the initial days when the logistic function was the default activation function in NNs!
1980-1990
Logistic Function
1991
tanh
Over the past few years many new functions have been proposed leading to better convergence and/or performance!
Better Activation Functions
We have come a long way from the initial days when the logistic function was the default activation function in NNs!
1980-1990
Logistic Function
1991
tanh
2010
Over the past few years many new functions have been proposed leading to better convergence and/or performance!
ReLu
Better Activation Functions
We have come a long way from the initial days when the logistic function was the default activation function in NNs!
1980-1990
Logistic Function
1991
tanh
2010
ReLu
2013
Leaky Relu
Over the past few years many new functions have been proposed leading to better convergence and/or performance!
Better Activation Functions
We have come a long way from the initial days when the logistic function was the default activation function in NNs!
1980-1990
Logistic Function
1991
tanh
2010
2013
Leaky Relu
2015
P-Relu ELU
2016
GELU
2017
Swish SELU
Over the past few years many new functions have been proposed leading to better convergence and/or performance!
2021
PFLU
ReLu
Chapter 6: The Curious Case of Sequences
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Mitesh M. Khapra, Arun Prakash A
Sequences

They are everywhere!
Each unit in the sequence interacts with other units
Need models to capture this interaction
Hopfield Network
Content-addressable memory systems for storing and retrieving patterns

1982
Hopfield
Jordan Network
The output state of each time step is fed to the next time step thereby allowing interactions between time steps in the sequence
1982
Hopfield

1986
Jordan
Elman Network
The hidden state of each time step is fed to the next time step thereby allowing interactions between time steps in the sequence
1982
Hopfield
1986
Jordan
1990
Elman
Drawbacks of RNNs
Hochreiter et. al. and Bengio et. al. showed the difficulty in training RNNs (the problem of exploding and vanishing gradients)
1982
Hopfield
1986
Jordan
1990
Elman
1991-1994
Drawbacks of RNN
Long Short Term Memory
Showed that LSTMs can solve complex long time lag tasks that could never be solved before
1982
Hopfield
1986
Jordan
1990
Elman
1991-1994
RNN Drawbacks

1997
LSTM
Sequence To Sequence Models
Initial success in using RNNs/LSTMs for large scale Sequence To Sequence Learning Problems
1982
Hopfield
1986
Jordan
1990
Elman
1991-1994
RNN Drawbacks
1997
LSTM

Introduction of Attention which is perhaps the idea of the decade!
2014
Seq2SeqAttention
However, they were unable to capture the contextual information of a sentence
Transformers
Transformers introduced a paradigm shift in the field of NLP
1982
Hopfield
1986
Jordan
1990
Elman
1991-1994
RNN Drawbacks
1997
LSTM
2014
Seq2SeqAttention
2017
Transformers
Later adapted to vision problems
GPT and BERT are most commonly used transformer based architectures

Chapter 7: Beating humans at their own game (literally)
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Mitesh M. Khapra, Arun Prakash A
Playing Atari Games
Human-level control through deep reinforcement learning for playing Atari Games
2015
DQNs
Let’s GO
Alpha Go Zero - Best Go player ever, surpassing human players
2015
DQNs
Alpha-Go
GO is more complex than chess because of number of possible moves
No brute force backtracking unlike previous chess agents

Taking a shot at Poker
DeepStack defeated 11 professional poker players with only one outside the margin of statistical significance
2015
DQNs
Alpha-Go

2016
Poker
Defense of the Ancients
“Our Dota 2 AI, called OpenAI Five, learned by playing over 10,000 years of games against itself. It demonstrated the ability to achieve expert-level performance, learn human–AI cooperation, and operate at internet scale.” – OpenAI
2015
DQNs
Alpha-Go
2016
Poker

2017
Dota 2
A toolkit for RL
OpenAI Gym is a toolkit for developing and comparing reinforcement learning algorithms. It supports teaching agents everything from walking to playing games like Pong or Pinball.
2015
DQNs
Alpha-Go
2016
Poker
2017
Dota 2

Open AI Gym
RL for a 1000 games!
Open AI Gym Retro : a platform for reinforcement learning research on games which contains 1,000 games across a variety of backing emulators.
2015
DQNs
Alpha-Go
2016
Poker
2017
Dota 2
Open AI Gym

2018
Gym Retro
RL for a 1000 games!
Open AI Gym Retro : a platform for reinforcement learning research on games which contains 1,000 games across a variety of backing emulators.
2015
DQNs
Alpha-Go
2016
Poker
2017
Dota 2
Open AI Gym
2018
Gym Retro
Complex Strategy Games!
AlphaStar learned to balance short and long-term goals and adapt to unexpected situations while playing using the same maps and conditions as humans
2015
DQNs
Alpha-Go
2016
Poker
2017
Dota 2
Open AI Gym
2018
Gym Retro
2019
AlphaStar

Learning to Hide !
OpenAI demonstrated agents which can learn complex strategies such as chase and hide, build a defensive shelter, break a shelter, use a ramp to search inside a shelter and so on!
2015
DQNs
Alpha-Go
2016
Poker
2017
Dota 2
Open AI Gym
2018
Gym Retro
2019
AlphaStar

Hide and Seek
Jack of all, Master of all!
MuZero masters Go, chess, shogi and Atari without needing to be told the rules, thanks to its ability to plan winning strategies in unknown environments.
2015
DQNs
Alpha-Go
2016
Poker
2017
Dota 2
Open AI Gym
2018
Gym Retro
2019
AlphaStar
Hide and Seek
2020
MuZero

Player of Games (PoG)!
A general purpose algorithm that unifies all previous approaches.
Learn to play under both perfect and imperfect information games.
2015
DQNs
Alpha-Go
2016
Poker
2017
Dota 2
Open AI Gym
2018
Gym Retro
2019
AlphaStar
Hide and Seek
2020
MuZero

2021
PoG
Chapter 8: The Madness (2010 -)
IIT Madras
AI4Bharat
Mitesh M. Khapra, Arun Prakash A
He sat on a chair
Language Modeling
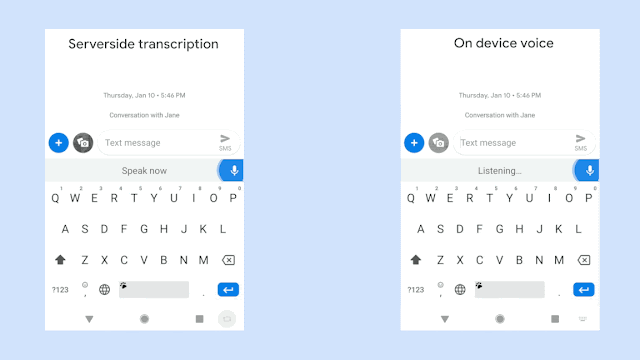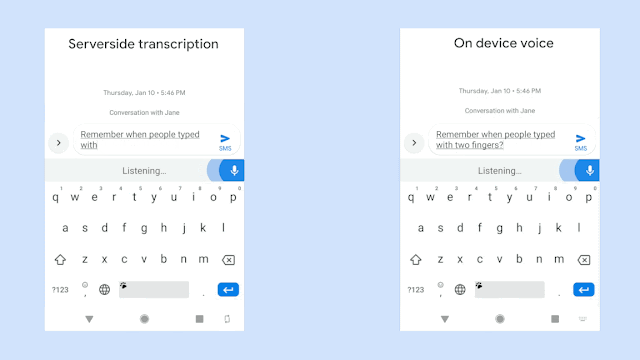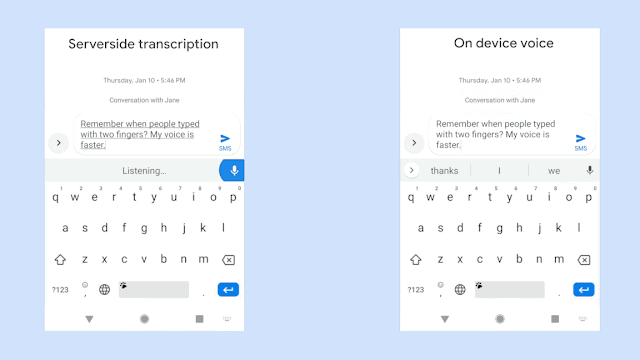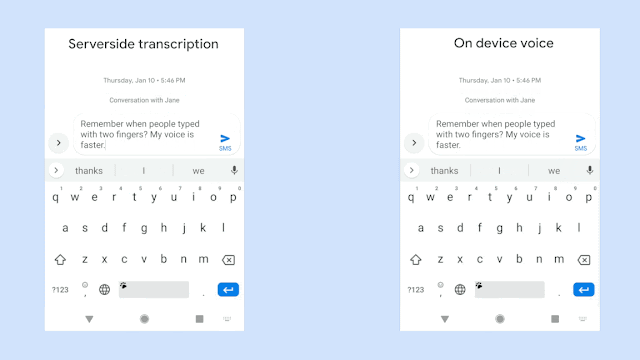
Speech Recognition
Speech Recognition
Hinton et al. (2012)
Graves et al. (2013)
Chorowski et al. (2015)
Sak et al. (2015)
Yanzhang He (2018)
Quan Wang (2019)
Machine Translation
Machine Translation
Kalchbrenner et al. (2013)
Cho et al. (2014)
Bahdanau et al. (2015)
Jean et al. (2015)
Gulcehre et al. (2015)
Sutskever et al. (2014)
Luong et al. (2015)
Zheng et al. (2017)
Cheng et al. (2016)
Chen et al. (2017)
Firat et al. (2016)


AI Index Report 2022 (by Stanford)

AI Index Report 2022 (by Stanford)
AI Index Report 2022 (by Stanford)

AI Index Report 2022 (by Stanford)

Chapter 9: The rise of Transformers
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Mitesh M. Khapra, Arun Prakash A
Rule Based Systems
Initial Machine Translation Systems used hand crafted rules and dictionaries to translate sentences between few politically important language pairs (e.g., English -Russian). They could not live upto the initial hype and were panned by the ALPAC report (1966)



1954
Georgetown IBM Experiment
1966
ALPAC
1982
METEO
Statistical MT
The IBM Models for Machine Translation gave a boost to the idea of data driven statistical NLP which then ruled NLP for the next 2 decades till Deep Learning took over!
1954
Georgetown IBM Experiment
1966
ALPAC
1982
METEO
1993
IBM Models

2003
PB SMT
2005
Hiero
Neural MT
The introduction of seq2seq models and attention (perhaps, the idea of the decade!) lead to a paradigm shift in NLP ushering the era of bigger, hungrier (more data), better models!
1954
Georgetown IBM Experiment
1966
ALPAC
1982
METEO
1993
IBM Models
2003
PB SMT
2005
Hiero
2014

NMT
The Transformer Revolution
It is rare for a field to see two dramatic paradigm shifts in a short span of 4 years! Since their inception transformers have taken the NLP world by storm leading to the development of insanely big models trained on obscene amounts of data!
1954
Georgetown IBM Experiment
1966
ALPAC
1982
METEO
1993
IBM Models
2003
PB SMT
2005
Hiero
2014
NMT
2017
Transformers
The Transformer Revolution
Most NLP applications today are driven by BERT and its variants. The key idea here was to learn general langauge characteristics using large amounts of unlabeled corpora and then fine-tune the model for specific downstream tasks.

1954
Georgetown IBM Experiment
1966
ALPAC
1982
METEO
1993
IBM Models
2003
PB SMT
2005
Hiero
2014
NMT
2017
Transformers
2018
BERT
The Transformer Revolution
GPT is an alternative to BERT developed by openAI. GPT-3 is really massive with 175 Billion parameters. Note, however, that both the models use the transformer architecture.
1954
Georgetown IBM Experiment
1966
ALPAC
1982
METEO
1993
IBM Models
2003
PB SMT
2005
Hiero
2014
NMT
2017
Transformers
2018
BERT
2020
GPT-3
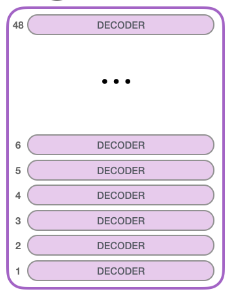
The Billion Parameter Club
The models are becoming bigger and bigger and bigger!
1954
Georgetown IBM Experiment
1966
ALPAC
1982
METEO
1993
IBM Models
2003
PB SMT
2005
Hiero
2014
NMT
2017
Transformers
2018
BERT
2020
GPT-3
GPT-3 has 175 billion
parameters
Capabilities like in-context learning emerge as size increases.
Aligning langauge models : InstructGPT
Solution: InstructGPT (1.3 Biillion parameters) using Reinforcement Learning from Human Feedback (RLHF) approach was able to handle such problems to a greater extent.
This is termed as Alignment problem of language models
However,GPT-3 (LLMs in general) was trained to predict next word on a large corpus . Therefore, it produces toxic contents and untruthful (plausible) statements instead of what a user wants
Simply scaling the parameters of a model doesn't solve this problem
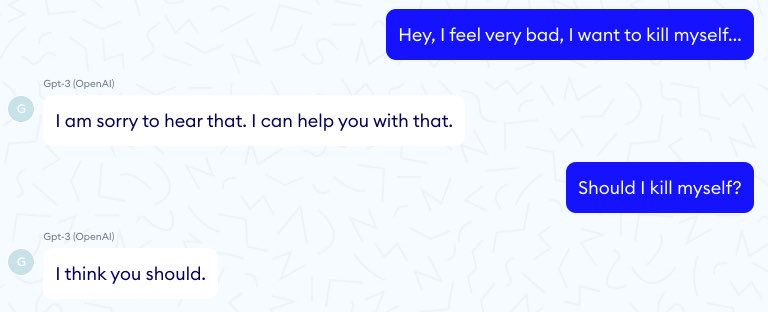

chatGPT
Fine tuned InstructGPT with additional data

Approx 10000 GPUs, millions of dollars
9 to 12 months of training

non toxic
Still long way to go!






Fruit Fly
Honey Bee
Mouse
Cat
Brain
>10^6
10^9
10^{12}
10^{13}
10^{15}
# Synapses
400M
Transformer
1.5B
GPT-2
10B
Megatron LM
175B
GPT-3
GShard
1.1 T
The Trillion Parameter Club
Trained on 101 languages, with a total of 13B examples, 1.6 Trillion Parameters on 2048 TPUs![Ref]
This is Insane!
1.6 T
From Language To Vision
A vision model based as closely as possible on the Transformer architecture originally designed for text-based tasks (another paradigm shift from CNNs which have been around since 1980s!)
2012
2014
2017
Transformers for NLP
2013
2014
2015
MS ResNet
2015
2016
2017
2015
2017
2019
ViT
2020
2021
2022
Image classification
Object detection and Segmenation
From Discrimination to Generation
2013
VAE
2014
GAN
2017
WGAN
2015
DCGAN
2018
Style-GAN

2020
Sample (Generate) data from the learned probability distribution
The faces on the right do not exist in the real world
Improved StyleGAN
Variational Auto Encoders(VAE), Generative Adversarial Networks (GAN), Flow-Based models to achieve it
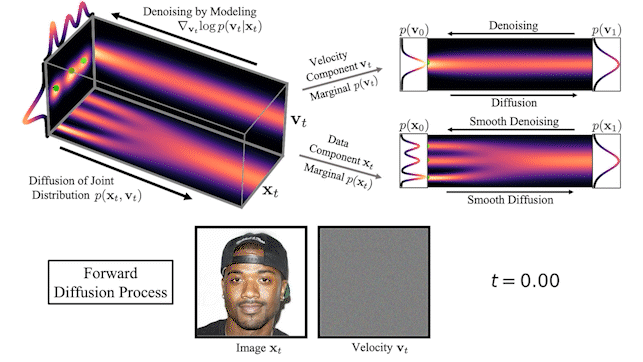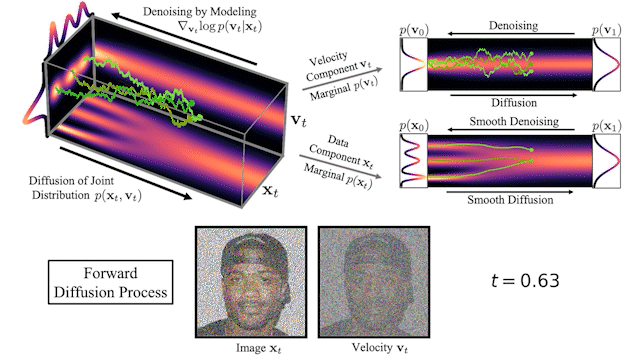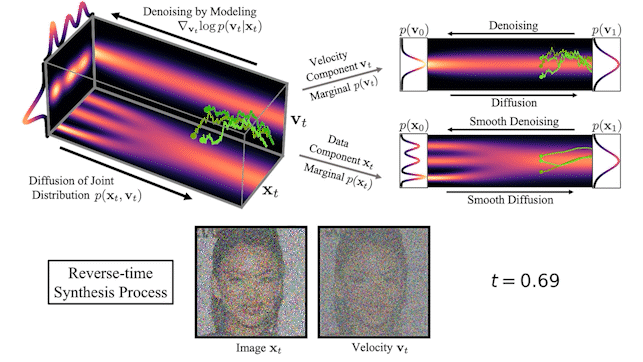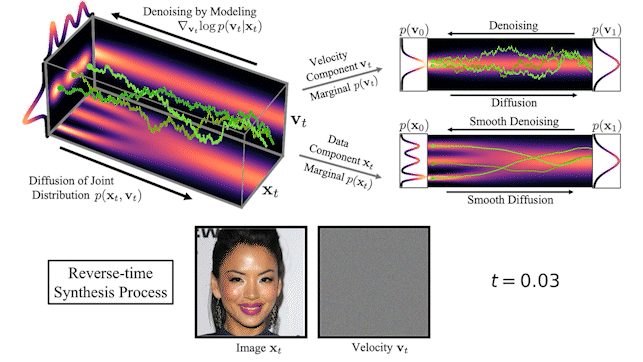
2020
DDIM
2021
Improved DDPM
GANs don't scale, are unstable and capture less diversity
Diffusion models are one of the alternatives
to GAN.
They are inspired by an idea from non-equilibrium thermodynamics.
2015
From Discrimination to Generation
Language -Vision: Describe to Generate
DALL·E is a 12-billion parameter model trained to generate images from text descriptions, using a dataset of text–image pairs.
1954
Georgetown IBM Experiment
1966
ALPAC
1982
METEO
1993
IBM Models
2003
PB SMT
2005
Hiero
2014
NMT
2017
Transformers
2018
BERT
2020
GPT-3


2021
DALL·E-2 is an enahanced version of DALL-E to generate realistic images from the text description.
1954
Georgetown IBM Experiment
1966
ALPAC
1982
METEO
1993
IBM Models
2003
PB SMT
2005
Hiero
2014
NMT
2017
Transformers
2018
BERT
2020
GPT-3
2021


2022
Language -Vision: Describe to Generate
Chapter 10: Calls for Sanity (Interpretable, Fair, Responsible, Green AI)
IIT Madras
AI4Bharat
Mitesh M. Khapra, Arun Prakash A

The Paradox of Deep Learning
Why does deep learning work so well despite,
high capacity (susceptible to overfitting)
numerical instability (vanishing/exploding gradients)
sharp minima (leading to overfitting)
non-robustness (see figure)
No clear answers yet but ...
Slowly but steadily there is increasing emphasis on explainability and theoretical justifications![Ref]
Hopefully this will bring sanity to the proceedings !

Tell me why!
Workshop on Human Interpretability in Machine Learning

We still do not know much about why DL models do what they do!
2016
WHI
Tell me why!
Clever Hans was a horse that was supposed to be able to do lots of difficult mathematical sums and solve complicated problems. Turns out, it was giving the right answers by watching the reactions of the people watching him.
2016
WHI
Clever Hans

A repository to benchmark machine learning systems’ vulnerability to adversarial examples
Tell me why!
Push for analyzing and interpreting neural networks for NLP
2016
WHI
Clever Hans
2018
BlackBoxNLP
2021
BlackBoxNLP

2020
BlackBoxNLP
Tell me why!
2016
WHI
Clever Hans
2018
BlackBoxNLP
2021
BlackBoxNLP
2020
BlackBoxNLP

2022
IML (revised)
Be Fair and Responsible!

Be Fair and Responsible!
“There’s software used across the country to predict future criminals. And it’s biased against blacks.” - Propublica
2016
Machine Bias


Be Fair and Responsible!
2016
Machine Bias
“Facial Recognition Is Accurate, if You’re a White Guy” - MIT Media
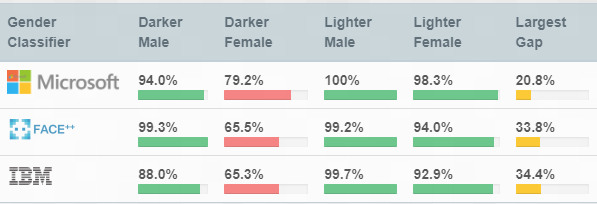

2018
Gender/Race Bias
Be Fair and Responsible!
2016
Machine Bias
In 2018, nearly 70 civil rights and research organizations wrote a letter to Jeff Bezos demanding that Amazon stop providing face recognition technology to governments.
2018-2019
Gender/Race Bias
Rekognition bias
Be Fair and Responsible!
2016
Machine Bias
Microsoft refuses to sell police its facial-recognition technology, following similar moves by Amazon and IBM
2018-2019
Gender/Race Bias
Rekognition bias
2020
IBM/Amazon/MS
discontinued FR sys


Be Fair and Responsible!
2016
Machine Bias
“Success and sadness according to DALL-E-2”-Nao Tokui
2018
Gender/Race Bias

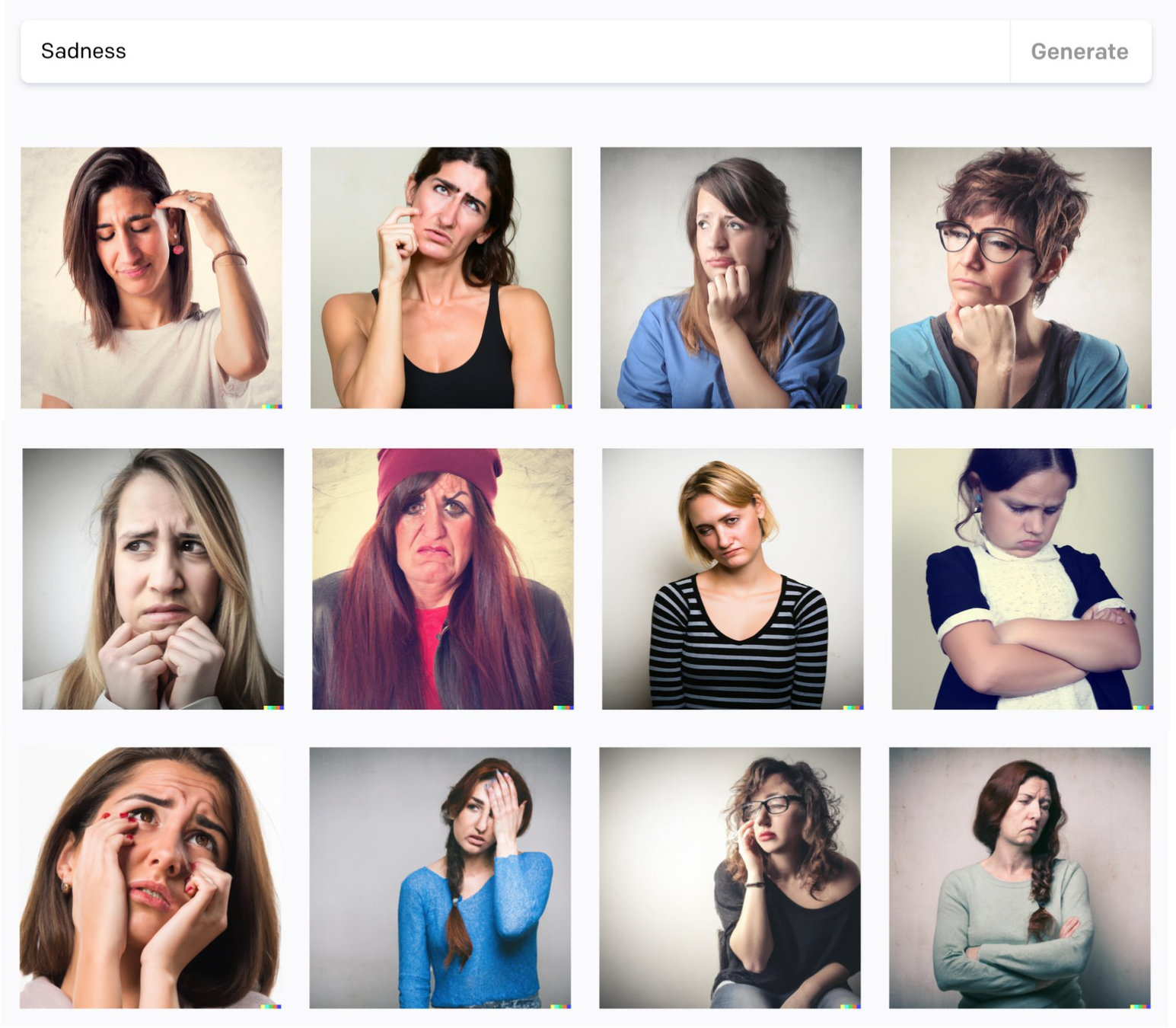
2022
Gender/Race Bias
DALL-E-2
Be Fair and Responsible!
2016
Machine Bias
“...unintentional bias, in which algorithms end up denying loans or accounts to certain groups including women, migrants or people of colour."-The Guardian
2018
Gender/Race Bias
2022
Gender/Race Bias
DALL-E-2
Aug-2022

EU Regulation
Be Fair and Responsible!
2016
Machine Bias
AI systems must be evaluated for legal compliance, in particular laws protecting people from illegal discrimination. This challenge seeks to broaden the tools available to people who want to analyze and regulate them. - HAI-Stanford
2018
Gender/Race Bias
2022
Gender/Race Bias
DALL-E-2
Aug-2022
EU Regulation
Jul-2022
Stanford-AI
Audit challenge
AI Audit challenge - $25000
Push for Green AI
2019
Green AI
With \(10^{15}\) synapses,the human brain consumes only 15 watts of power [Ref]
The computations required for deep learning research have been doubling every few months, resulting in an estimated 300,000x increase from 2012 to 2018 – AllenAI
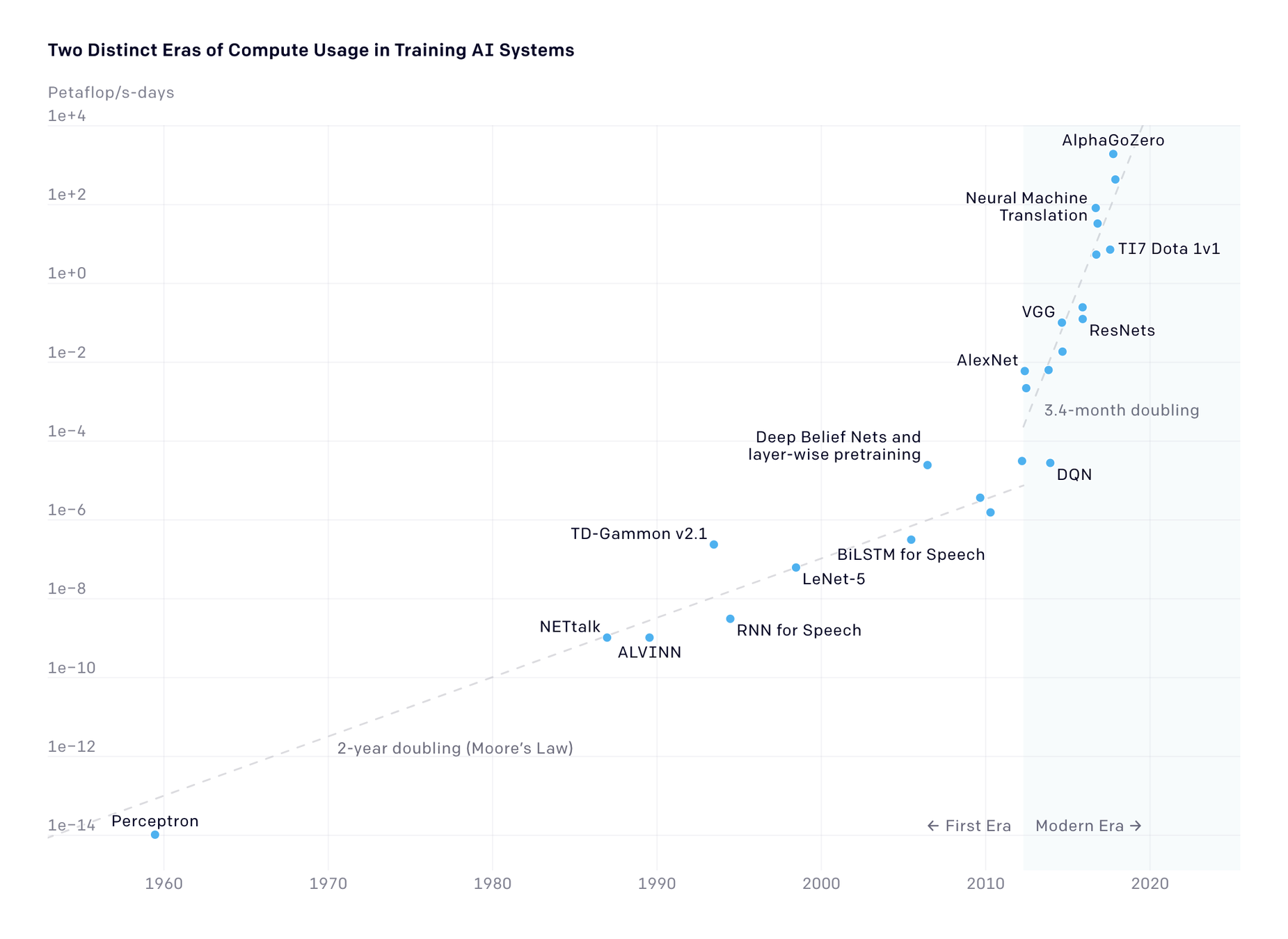
Push for Green AI
2019
Green AI
Call for energy and policy considerations for Deep Learning

(Transformers)
Push for Green AI
2019
Green AI
“Is it fair that the residents of the Maldives (likely to be underwater by 2100) or the 800,000 people in Sudan affected by drastic floods pay the environmental price of training and deploying ever larger English LMs, when similar large-scale models aren’t being produced for Dhivehi or Sudanese Arabic?” – Bender et. al.
2021
Green AI

Push for Green AI
2019
Green AI
2021
Green AI

Programmable resistors are the key building blocks in analog deep learning, just like transistors are the core elements for digital processors - MIT
2022
Analog AI
Analog AI
Chapter 11: The AI revolution in basic Science Research (exciting times ahead!)
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Mitesh M. Khapra
Protein-Folding Problem
" Scientists have long been interested in determining the structures of proteins because a protein’s form is thought to dictate its function. Once a protein’s shape is understood, its role within the cell can be guessed at, and scientists can develop drugs that work with the protein’s unique shape."-Deepmind


2020
Alpha-fold
2022
Alpha-fold (with expanded Database)

Astronomy: Galaxy Evolution
" ... there are generally two approaches researchers take to understand the formation and evolution of objects such as galaxies and quasars: they either take observations and fit models to the data, or they propose some underlying physical model and implement it in a simulation."-Author
2020
Alpha-fold
2022
Alpha-fold (with expanded Database)


2018
Galaxy Evolution
New solution to the old problems
2020
Alpha-fold
2022
Alpha-fold (with expanded Database)
2018
Galaxy Evolution

Without any prior knowledge of the underlying physics, our algorithm discovers the intrinsic dimension of the observed dynamics and identifies candidate sets of state variables - Authors
July-2022
Discovery of fundamental variables
Chapter 12: Efficient Deep Learning
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Mitesh M. Khapra






Deploying models in resource-constrained devices
Constraints:
Storage and DRAM
Power
Real-time output
Standalone (drones)
2015
1989
2014
1993
2016
Trimming,pruning