CS6910: Fundamentals of Deep Learning
Lecture 16: Transformers:Multi-headed self-attention, cross attention
Mitesh M. Khapra, Arun Prakash A


AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Module 16.1 : Limitations of sequential model
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Mitesh M. Khapra, Arun Prakash A
I
enjoyed
the
movie
transformers
Encoder RNN
Decoder RNN
The final state \(h_5\) is called a concept vector, thought vector or annotation
Sequence to Sequence
Sequence to Sequence
I
enjoyed
the
movie
transformers
Encoder RNN
Decoder RNN
Naan
transfarmar
padaththai
rasiththen
Naan
transfarmar
padaththai
The final state \(h_5\) is called a concept vector, thought vector, context vector or annotation
However, it doesn't care about the alignment of words between source sentence and target sentence
Attention mechanism resolves this.
Attention: A quick tour
I
enjoyed
the
film
transformers
RNN Encoder
Attention a quick Tour:
I
enjoyed
the
film
transformers
RNN Encoder
Suppose that we create a copy of these hidden state vectors \((h_1,\cdots,h_5\)) and make those available to the decoder.
Once all these vectors are available to the decoder we can drop the encoder block (until decoding completes)
The attention mechanism consumes these vectors as one of the inputs.
\(n\), number of words
\(t\)= time step for decoder
Naan
I
enjoyed
the
film
transformers
<Go>
Naan
transfarmar
I
enjoyed
the
film
transformers
<Go>
Naan
transfarmar
I
enjoyed
the
film
transformers
padaththai
<Go>
Naan
transfarmar
I
enjoyed
the
film
transformers
padaththai
rasiththen
<Go>
Naan
transfarmar
I
enjoyed
the
film
transformers
padaththai
rasiththen
Alignment of words:
Naan
transfarmar
padaththai
rasiththen
the
I
enjoyed
film
transformers
<Go>
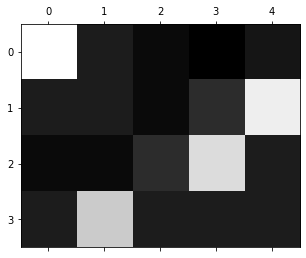
the
I
enjoyed
film
transformers
Naan
transfarmar
padaththai
rasiththen
Naan
transfarmar
I
enjoyed
the
film
transformers
padaththai
rasiththen
QP: Can \(h_{i}\),for all \(i\), be computed in parallel ?
QP: Can \(\alpha_{ti}\) be computed in parallel for all \(i\) at time step \(t\)?
<Go>
Yes. \(h_i\) is available for all \(i\) and \(s_{t-1}\) is also available at time step \(t\).
No!
Take away: Attention can be parallelized
Approaches to implement score function
Content-Base attention
Additive (concat) attention
Dot product attention
Scaled Dot product attention
All score functions take in two vectors and produce a scalar.
Major Limitation
Everything about the RNN based sequence-to-sequence model seems good so far.
They performed well for translation using an attention mechanism.
However, there is a major limitation in training the model.
Given a training example, we can't parallelize the sequence of computations across time steps.
I
enjoyed
the
movie
transformers
Naan
transfarmar
padaththai
rasiththen
Naan
transfarmar
padaththai
Wishlist: come up with a new architecture that incorporates the attention mechanism and also allows parallelization (and of course, get rid of vanishing/exploding gradient problems)
Module 16.2 : Attention is all you need
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Mitesh M. Khapra
Transformers: Attention is all you need

*RNN seq2seq models
I
enjoyed
the
movie
transformers
Naan
transfarmar
padaththai
rasiththen
Naan
transfarmar
padaththai
Transition to Transformers
Encoder
Decoder
Naan
transfarmar
padaththai
rasiththen
Naan
transfarmar
padaththai
Transition to Transformers
Encoder
Decoder
With Attention
I
enjoyed
the
movie
transformers
Naan
transfarmar
padaththai
rasiththen
Transition to Transformers
Encoder
Decoder
Feed Forward Networks
Self-Attention
Self-Attention
Encoder-Decoder Attention
Feed Forward Networks
We will see each of these components (and a few more) one at a time in detail and connect them together to synthesize the final architecture
Word Embedding
I
enjoyed
the
movie
transformers
Self-Attention
Encoder
Self-Attention
Note that the inputs are vectors (word embeddings) and the outputs are also vectors
| 1 | 0 | 0 |
|---|
| 0 | 1 | 0 |
|---|
| 1 | 1 | 0 |
|---|
| 1 | 0 | 1 |
|---|
| 1 | 1 | 1 |
|---|
Well, we know what attention is. All it requires is a pair of vectors as input.
You can think of these word embeddings as \(h_i\) in RNN encoder (if you wish to compare)
Self-Attention
Let's take another example sentence
"The animal didn't cross the street because it was too tired".
The word "it" in the sentence refers to "Animal" or "Street"?
We know "it" is referring to the word "Animal"
Let's modify the sentence:
"The animal didn't cross the street because it was congested".
Now the word "it" is referring to the word "Street"
Therefore, it is important to establish a strong connection between the word "it" to the word "street" or "animal" based on the context.
It calls for an Attention mechanism. That's why it is called a self-attention (to distinguish from cross-attention which we will see later)
The goal
Given a word in a sentence, we want to compute the relational score between the word and the rest of the words in the sentence.
| The | animal | didn't | cross | the | street | bacause | it | |
|---|---|---|---|---|---|---|---|---|
| The | ||||||||
| animal | ||||||||
| didn't | ||||||||
| cross | ||||||||
| the | ||||||||
| street | ||||||||
| because | ||||||||
| it |
The goal
Given a word in a sentence, we want to compute the relational score between the word and the rest of the words in the sentence....
| The | animal | didn't | cross | the | street | bacause | it | |
|---|---|---|---|---|---|---|---|---|
| The | 0.6 | 0.1 | 0.05 | 0.05 | 0.02 | 0.02 | 0.02 | 0.1 |
| animal | 0.02 | 0.5 | 0.06 | 0.15 | 0.02 | 0.05 | 0.01 | 0.12 |
| didn't | 0.01 | 0.35 | 0.45 | 0.1 | 0.01 | 0.02 | 0.01 | 0.03 |
| cross | . | |||||||
| the | . | |||||||
| street | . | |||||||
| because | . | |||||||
| it | 0.01 | 0.6 | 0.02 | 0.1 | 0.01 | 0.2 | 0.01 | 0.01 |
...such that the score is higher if they are related contextually
The goal
| The | animal | didn't | cross | the | street | bacause | it | |
|---|---|---|---|---|---|---|---|---|
| The | 0.6 | 0.1 | 0.05 | 0.05 | 0.02 | 0.02 | 0.02 | 0.1 |
| animal | 0.02 | 0.5 | 0.06 | 0.15 | 0.02 | 0.05 | 0.01 | 0.12 |
| didn't | 0.01 | 0.35 | 0.45 | 0.1 | 0.01 | 0.02 | 0.01 | 0.03 |
| cross | . | |||||||
| the | . | |||||||
| street | . | |||||||
| because | . | |||||||
| it | 0.01 | 0.6 | 0.02 | 0.1 | 0.01 | 0.2 | 0.01 | 0.01 |
We can think of headers in the first column as \(s_{i}\) and headers in the first row as \(h_j\) (just for convenience)
The goal
| The | animal | didn't | cross | the | street | bacause | it | |
|---|---|---|---|---|---|---|---|---|
| The | 0.6 | 0.1 | 0.05 | 0.05 | 0.02 | 0.02 | 0.02 | 0.1 |
| animal | 0.02 | 0.5 | 0.06 | 0.15 | 0.02 | 0.05 | 0.01 | 0.12 |
| didn't | 0.01 | 0.35 | 0.45 | 0.1 | 0.01 | 0.02 | 0.01 | 0.03 |
| cross | . | |||||||
| the | . | |||||||
| street | . | |||||||
| because | . | |||||||
| it | 0.01 | 0.6 | 0.02 | 0.1 | 0.01 | 0.2 | 0.01 | 0.01 |
However, now both the vectors \((s_i)\) and \((h_j)\), for all \(i,j\) are available for all the time (whereas in the seq2seq model, \(h_j\) for all \(j\) were available and \(s_i\) was obtained one at a time)
Does it allow us to compute the values for the rows parallelly (i.e., all at a time) ?
Choice of Attetnion function
Recall, the score function \(e_{jt}\) used in the seq2seq model
-
Two Linear transformations
There are three vectors \((s,h,v)\) involved in computing the score at each time step (of decoder)
-
One non-linearity
Choice of Attetnion function
-
Two Linear transformations
There are three vectors \((s,h,v)\) involved in computing the score for each time step (of decoder)
-
One non-linearity
-
Finally Dot-Product
Choice of Attetnion function
However, the input to the self-attention module is only the word embeddings \(h_j\) for all \(j\)
So, we need to get three vectors for each word embedding. How do we do it?
Matrix transformation!. How many matrices do we need?
3
The value of elements in the matrix?
-
Two Linear transformations
There are three vectors \((s,h,v)\) involved in computing the score for each time step (of decoder)
-
One non-linearity
-
Finally Dot-Product
Transformation Matrices
\(q_j\) is called query vector for the word embedding \(h_j\)
\(k_j\) is called key vector for the word embedding \(h_j\)
\(v_j\) is called value vector for the word embedding \(h_j\)
\(W_Q,W_K \ and \ W_V\) are called respective linear transformation (parameter) matrices.

Animal \(\mathbb{R^3}\)
It \(\mathbb{R^3}\)

Animal \(\mathbb{R^2}\)
It \(\mathbb{R^2}\)
I
enjoyed
the
movie
transformers
Self-Attention
| 1 | 0 | 0 |
|---|
| 0 | 1 | 0 |
|---|
| 1 | 1 | 0 |
|---|
| 1 | 0 | 1 |
|---|
| 1 | 1 | 1 |
|---|
Let's focus on first calculating the first output from self-attention layer
I
transformers
Self-Attention
| 1 | 0 | 0 |
|---|
| 1 | 1 | 1 |
|---|
| 0.3 | 0.2 |
|---|
| 0.1 | 0.5 |
|---|
| -0.1 | 0.25 |
|---|
| 0.11 | 0.89 |
|---|
| 0 | 0.4 |
|---|
| 0.2 | 0.7 |
|---|
Fixed
variable
Score func: dot product
What about the \(z_2\)?
Let's focus on first calculating the first output from self-attention layer
I
transformers
Self-Attention
| 1 | 0 | 0 |
|---|
| 1 | 1 | 1 |
|---|
Let's focus on first calculating the first output from self-attention layer
| 0.3 | 0.2 |
|---|
| 0.1 | 0.5 |
|---|
| -0.1 | 0.25 |
|---|
| 0.11 | 0.89 |
|---|
| 0 | 0.4 |
|---|
| 0.2 | 0.7 |
|---|
Fixed
variable
Repeat the procedure for all other \(z\).
Score func: dot product
Wait, can we vectorize all these computations and compute the outputs (\(z_1,z_2,\cdots,z_T\)) in one go?
Wait, can we vectorize all these computations and compute the outputs (\(z_1,z_2,\cdots,z_T\)) in one go?
Wait, can we vectorize all these computations and compute the outputs (\(z_1,z_2,\cdots,z_T\)) in one go?
Where \(d_k\) is the dimension of key vector.
Since \(d_k\) scales the values of \(Q^TK\), it is called a scaled-dot product.
Vectorized Output
Scaled Dot Product
Head
Two-head Attention
Scaled Dot Product
Head-1
Scaled Dot Product
Head-2
Motivation for Multi-Head attention
What is the significance of having more than one filter/kernel in a CNN layer?

To learn more abstract representations, capture more meaningful interactions between inputs
Similarly, we can have more than one self-attention heads with different parameter matrices \((W_Q^i,W_K^i,W_V^i)\) with a hope that it learns subtle contextual information.
This motivates "Multi-head Attention", which is a simple extension of single-head attention
Like, each kernel independently learns its feature in CNN, each head independently computes the attention in Transformers. (Parallel computation!)
Motivation

Single-Head
The word "it" is strongly connected to the word "was".
Link to the colab: Tensor2Tesnor
Motivation
Two-Head
The word "it" is strongly connected to the word "was" in the first head

The word "it" is strongly connected to the word "animal" in the second head.
So it is evident (empirically) that adding more than one attention helps in capturing different contextual information of the sentence
So, the multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.
A little more detail
The dimension of \(q_j\) is much less than \(h_j\). In fact,
The word embedding \(h_j \in \mathbb{R}^{512}\) is projected to a low dimensional representation subspace of size \(q_j,k_j,v_j \in \mathbb{R}^{64}\) by the matrices \(W_Q,W_K\) and \(W_V\).
Scaled Dot Product
Attention
Scaled Dot Product
Attention
Two head Attention
Concatenate
Linear
How do we extend this to multi-head attention?
Recall How \(Q,K,V\) are obtained from \(H\).
Scaled Dot Product
Attention
Scaled Dot Product
Attention
Scaled Dot Product
Attention
Concatenate (:\(T \times 512\))
Linear
Multi-Head Attention
Concatenate (:\(T \times 512\))
Linear
Multi-Head Attention
Scaled Dot Product
Attention
Scaled Dot Product
Attention
Scaled Dot Product
Attention
Concatenate (:\(T \times 512\))
Linear
Multi-Head Attention
Scaled Dot Product
Attention
Scaled Dot Product
Attention
Scaled Dot Product
Attention
The input is projected into \(h=8\) different representation subspaces.
So, the multi-head attention allows the model to jointly
attend to information from different representation
subspaces at different positions.
I
enjoyed
the
movie
transformers
Encoder
Feed Forward Network
Self-Attention
Back to Basic Block
I
enjoyed
the
movie
transformers
Encoder
Feed Forward Network
Multi-Head Attention
A slight change in terminology. These two components form an encoder layer. The encoder is composed of a stack of \(N=6\) layers
Therefore, each layer in the encoder is composed of two sublayers, namely, multi-head attention and feed forward neural networks
I
enjoyed
the
movie
transformers
Multi-Head Attention
FFN
1
FFN
2
FFN
5
FFN
4
FFN
3

I
enjoyed
the
movie
transformers
Multi-Head Attention
FFN
1
FFN
2
FFN
5
FFN
4
FFN
3
I
enjoyed
the
movie
transformers
Multi-Head Attention
FFN
1
FFN
2
FFN
5
FFN
4
FFN
3
Identical network for each position \(z_i\)
Let's calculate the number of learnable parameters in the encoder layer
Feed Forward Network
Multi-Head Attention
I
enjoyed
the
movie
transformers
Therefore, about 3 million parameters per layer
Considering 8 heads
Encoder Stack
The encoder is composed of \(N\) identical layers and each layer is composed of 2 sub-layers.
Number of Parameters: \(N \times 3 \times 10^6\)
Number of Parameters: \(6 \times \) 3 million
about 18 million parameters
The computation is parallelized in the horizontal direction (i.e., within a training sample) of the encoder stack, not along the vertical direction.
I
enjoyed
the
movie
transformers
Layer-1
Layer-2
Layer-6
Let us denote the output sequence of vectors from the decoder as \(e_j\), for \(j=1,\cdots,?\)
Decoder
I
enjoyed
the
movie
transformers
Encoder
Decoder
Naan
transfarmar
padaththai
rasithen
What will be the output dimension?
Decoder Stack
Naan
transfarmar
padaththai
rasithen
Layer-1
Layer-2
Layer-6
The decoder is a stack of \(N=6\) Layers. However, each layer is composed of three sublayers.
Feed Forward Network
Masked Multi-Head (Self)Attention
Multi-Head (Cross) Attention
Teacher Forcing
Why the target sentence is being fed as one of the inputs to the decoder?
Usually, we use only the decoder's previous prediction as input to make the next prediction in the sequence.
However, the drawback of this approach is that if the first prediction goes wrong then there is a high chance the rest of the predictions will go wrong (because of conditional probability)
Of course, the algorithm has to fix this as training progresses. But, it takes a long time to traing the model.
The other approach is to use so-called "Teacher Forcing" algorithm. Let's say the target language is English
Ground Truth
I
enjoyed
the sunshine
I
enjoyed
the film
last night
This will lead to an accumulation of errors.
transformer
D
D
D
D
D
Masked (Self) Attention
With one important difference:
Recall that in self-attention we computed the query, key, and value vectors \(q,k\&v\) by multiplying the word embeddings \(h_1,h_2,\cdots,h_T\) with the transformation matrices \(W_Q,W_K,W_V\),respectively.
The same is repeated in the decoder layers. This time the \(h_1,h_2,\cdots,h_T\) are the word embeddings of target sentence. But,
With one important difference: Masking to implement the teacher-forcing approach during training.
Note: Encoder block also uses masking in attention sublayer in practice to mask the padded tokens in sequences having length < T
Of course, we can't use teacher forcing during inference. Instead, the decoder act as a auto-regressor.
Recall that in self-attention we computed the query, key, and value vectors \(q,k\&v\) by multiplying the word embeddings \(h_1,h_2,\cdots,h_T\) with the transformation matrices \(W_Q,W_K,W_V\),respectively.
The same is repeated in the decoder layers. This time the \(h_1,h_2,\cdots,h_T\) are the word embeddings of target sentence. But,
Masked Multi-Head Self Attention
How do we create the mask? Where should we incorporate it? At the input or output or intermediate?
Assign zero weights \(\alpha_{ij}=0\) for the value vectors \(v_j\) to be masked in a sequence
Let us denote the mask matrix by \(M\), then
Masked Multi-Head (Self)Attention
Masked Multi-Head (Self)Attention
Masked Multi-Head (Self)Attention
Naan
transfarmar
padaththai
rasiththen
<Go>
Naan
transfarmar
padaththai
rasiththen
<Go>
Naan
transfarmar
padaththai
rasiththen
<Go>
Masking is done by inserting negative infinite at the respective positions.

This actually forms an triangular matrix with one half all zeros and the other half all negative infinity
Masked Multi-Head Cross Attention
Now we have the vectors \(\{s_1,s_2,\cdots,s_T\}\) coming from the self-attention layer of decoder.
We have also a set of vector \( \{e_1,e_2,\cdots,e_T\}\) coming from top layer of encoder stack that is shared with all layers of decoder stack.
Again, we need to create query, key and value vectors by applying the linear transformation matrices \(W_{Q_2},W_{K_2},\ \& \,W_{V_2}\) on these vectors \(s_i\) and \(e_j\).
Therefore, it is called Encoder-Decoder attention or cross attention.
We construct query vectors using vectors from self-attention layer,\(S\) and key,value vectors using vectors from the encoder,\(E\)
We compute the multi-head attention using \(Q_2,K_2,V_2\) and concatenate the resulting vectors.
Finally, we pass the concatenated vectors through the feed-forward neural network to obtain the output vectors \(O\)
Feed Forward Network
Masked Multi-Head (Self)Attention
Multi-Head (Cross) Attention
Bottom most decoder layer
Naan
transfarmar
padaththai
rasiththen
<Go>
Feed Forward Network
Naan
transfarmar
padaththai
rasiththen
<Go>
Number of Parameters:
About 2 million parameters from FFN layer
About 1 million parameters from Masked-Multi Head Attention layer
About 1 million parameters from Multi Head Cross Attention layer
About 4 million parameter per decoder layer
Decoder output
Feed Forward Network
Linear \(W_D\)
Softmax
The output from the top most decoder layer is linearly transformed by the matrix \(W_D\) of size \(512 \times |V|\) where \(|V|\) is the size of the vocbulary.
The probability distribution for the predicted words is obtained by applying softmax function.
This alone contributes about 19 million parameters of the total 65 million parameters of the architecture.
Module 1.3 : Positional Encoding
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Mitesh M. Khapra, Arun Prakash A
Positional Encoding
The position of words in a sentence was encoded in the hidden states of RNN based sequence to sequence models.
However, in transformers, no such information is available to either encoder or decoder. Moreover, the output from self-attention is permutation-invariant.
How do we embed positional information in the word embedding \(h_j\) (of size 512)?
I
Enjoyed
So, it is necessary to encode the positional information.
Positional Encoding
I
How do we fill the elements of the positional vector \(p_0\)?
Could it be a constant vector (i.e, all elements are of constant (position) value \(j\), for \(p_j\))?
Can we use one hot encoding for the position \(j\), \(j=0,1,\cdots,T\)?
or learn embedding for all possible positions?
Not suitable if the sentence length is dynamic.
Sinusoidal encoding function
Hypothesis: Embed a unique pattern of features for each position \(j\) and the model will learn to attend by the relative position.
How do we generate the features?
For the fixed position \(j\), we use the \(sin()\) function if \(i\) is even and \(cos()\) if \(i\) is odd
Let's evaluate the function \(PE_{(j,i)}\) for \(j={0,1,\cdots,8}\) and \(i={0,1,\cdots,63}\)
Then, we can visualize this matrix as a heat map.

This alternating 0's and 1's will be added to the first word(embedding) of all sentences (sequences)
This alternating 0's and 1's will be added to the first word(embedding) of all sentences.
Let's ask some interesting questions
| I | Enjoyed | the | film | transformer |
|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 |
| 1 | 0 | 1 | 2 | 3 |
| 2 | 1 | 0 | 1 | 2 |
| 3 | 2 | 1 | 0 | 1 |
| 4 | 3 | 2 | 1 | 0 |
Distance matrix
I
Enjoyed
the
film
transformer
The interesting observation is that the distance increases on the left and right of 0 (in all the rows) and is symmetric at the centre position of the sentence
Does the PE function satisfy this property?
Let's verify it graphically..
Does one-hot encoding satisfy this
property?
No.
The Euclidean distance between any two vectors (independent of their position) is always \(\sqrt{2}\).




At every even indexed column,\((i=0,2,4,\cdots,512)\), we have a sine function with decreasing frequency (or increasing wavelength) as \(i\) increases.
Similarly, at odd indexed column,\((i=1,3,5,\cdots,511)\), we have a cosine function with decreasing frequency (or increasing wavelength) as \(i\) increases.
Wavelength progress from \(2\pi \rightarrow 10000 2\pi\)
Module 16.4 : Training the Transformer
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Mitesh M. Khapra, Arun Prakash A
For a (rough) comparison, we may think of the transformer architecture as composed of attention layers and hidden layers.

Attention layer
Attention layer
Attention layer
Linear
+
Softmax
Then there are two hidden layers and one attention layer in every encoder layer
For a (rough) comparison, we may think of the transformer architecture is composed of attention layers and hidden layers.
Attention layer
Attention layer
Attention layer
Linear
+
Softmax
How do we ensure the gradient flow across the network?
How do we speed up the training process?
Residual Connections!
Normalization!
Then there are two hidden layers and attention layer in every encoder layer and 2 attention layers and 2 hidden layers in every decoder layer. Then, the network is deep with 42 layers (6 enc + 6 dec)
Batch Normalization at
Accumulated activations for \(m\) training samples
Let \(x_i^j\) denotes the activation of \(i^{th}\) neuron for \(j^{th}\) training sample

We have three variables \(l,i, j\) involved in the statistics computation. Let's visualize these as three axes that form a cube.
Let us associate an accumulator with \(l^{th}\) layer that stores the activations of batch inputs.
Batch Normalization at
Accumulated activations for \(m\) training samples
Let \(x_i^j\) denotes the activation of \(i^{th}\) neuron for \(j^{th}\) training sample
We have three variables \(l,i, j\) involved in the statistics computation. Let's visualize these as three axes that form a cube.
Let us associate an accumulator with \(l^{th}\) layer that stores the activations of batch inputs.
Can we apply batch normalization to transformers?
Of course, yes. However, there are some limitations to BN.
The accuracy of estimation of mean and variance depends on the size of \(m\). So using a smaller size of \(m\) results in high error.
Because of this, we can't use a batch size of 1 at all (i.e, it won't make any difference, \(\mu_i=x_i,\sigma_i=0\))
Fortunately, we have another simple normalization technique called Layer Normalization that works well.
Other than this limitation, it was also empirically found that the naive use of BN leads to performance degradation in NLP tasks (source).
There was also a systematic study that validated the statement and proposed a new normalization technique (by modifying BN) called powerNorm.
Layer Normalization at \(l^{th}\) layer

The computation is simple. Take the average across outputs of hidden units in the layer. Therefore, the normalization is independent of #of samples in a batch.
This allows us to work with a batch size of 1 (if needed as in the case of RNN)
The complete Layer
Encoder
Feed Forward Network
Multi-Head Attention
The complete Layer
Encoder
Feed Forward Network
Multi-Head Attention
Add & Layer Norm
Add & Layer Norm
Add residual connection and layer norm block after every Multi-Head attention, feed-forward network, cross attention block

The Transformer Architecture
The output from the top encoder layer is fed as input to all the decoder layers to compute multi-head cross attention.
The input embedding for words in a sequence is learned while training the model. (No pretrained embedding model like Word2Vec was used).
This amounts to an additional set of weights in the model.
The positional information is encoded and added with input embedding (this function can also be parameterized)
Training the Transformer
ADAM
Defaults
However, the learning rate \(\eta\) was changed across time steps.
Module 16.5 : Warm-up strategy
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Mitesh M. Khapra, Arun Prakash A
Attempt-1: Using a decaying learning rate

Let's assume that the model is taking too long to converge (i.e., the error rate decays very slowly, especially for the first 4000 steps)
So we decide to see whether increasing the learning rate would be of any help.
Let's say we start off training the model with mini-batches
Attempt-2: Using a growing learning rate
Let's say the error rate decays significantly well for the first 4000 steps and increases thereafter..
So, what will be our next attempt?
We increase the learning linearly by setting


Increase the learning rate for the first 4000 steps and decrease it thereafter.
Increase the learning rate for the first 4000 steps and decrease it thereafter.

How do we combine both?
This is counterintuitive. We usually start with a high learning rate and keep decreasing it.
However, here we do a 'warm-up' during initial steps and decrease the learning rate after "warm-up steps (4000)"
Well, "Warm-up steps" is another hyper-parameter.
Learning rate with Warmup Strategy
Notice that the red curve is decreasing monotonically and the blue curve is increasing monotonically.
So, it is true that, after the warmup steps, the blue curve is always greater than the red curve.
This allows us to rewrite the learning rate schedule as follows
Scaling factor
Learning rate with Warm-Up Strategy

warmupSteps=4000
Is warm-up specific to ADAM?

What happens to the gradients with and without warm-up?

The transformer architecture was actually proposed for neural machine translation tasks. It performed significantly well with a lesser training time due to paralleization.
Can we adopt the same for other NLP tasks like language understanding, question-answering, text classification?
Can we adopt the same for other Computer vision tasks like segmentation, classification?
Of course, yes!.