Encoder-Decoder models, BART, GPT2, T5, Choices that affect performance
Mitesh M. Khapra, Arun Prakash A


AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Introduction to Large Language Models
Module 1 : From BERT to BART
Mitesh M. Khapra, Arun Prakash A
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
So far, we have learned two approaches with two different objectives for language modelling
BERT is good at comprehension tasks like questions answering because of its bidirectional nature
GPT is good at text generation because of its unidirectional nature
Why don't we take the best of both worlds?
BERT and its variations
GPT and its variations
Multi-Head Attention
Feed forward NN
Add&Norm
Add&Norm
\(x_1,<mask>,\cdots,x_{T}\)
\(P(x_2=?)\)
Multi-Head masked Attention
Feed forward NN
Add&Norm
Add&Norm
\(x_1,x_2,\cdots,x_{i-1}\)
\(P(x_i)\)
BERT
GPT
Multi-Head Attention
Feed forward NN
Add&Norm
Add&Norm
\(x_1,<mask>,\cdots,x_{T}\)
\(P(x_2=?)\)
Multi-Head masked Attention
Feed forward NN
Add&Norm
Add&Norm
\(x_1,x_2,\cdots,x_{i-1}\)
\(P(x_i)\)
Multi-Head Attention
Feed forward NN
Add&Norm
Add&Norm
Multi-Head cross Attention
Feed forward NN
Add&Norm
Add&Norm
Multi-Head Maksed Attention
Add&Norm
\(x_1,<mask>,\cdots,x_{T}\)
\(<go>\)
\(.,P(x_2|x_1,).,\)
Multi-Head Attention
Feed forward NN
Add&Norm
Add&Norm
Multi-Head cross Attention
Feed forward NN
Add&Norm
Add&Norm
Multi-Head Maksed Attention
Add&Norm
\(x_1,<mask>,\cdots,x_{T}\)
\(<go>\)
\(p(x_2|x_1)\)
A vanilla transformer architecture with GELU activation fuction.
The decoder predicts the entire sequence and computes the loss (as in the case of GPT) over the entire sequence.
The input sequence is corrupted in multiple ways: random masking, token deletion, document rotation and so on
The encoder takes in the corrupted sequence
One can think of this as a denoising-autoencoder.
GPT2: Prompting Large Language Models
Using any of these pre-trained models for downstream tasks requires us to independently fine-tune the parameters of the model for each task (objective might differ for each downstream task)
BERT, GPT,BART
Dataset
BERT, GPT,BART
BERT, GPT,BART
BERT, GPT,BART
That is, we make a copy of the pre-trained model for each task and fine-tune it on the dataset specific to that task
Pre-training
Fine-tuning
Standford Sentiment Tree Bank (SST)
SNLI
LAMBADA
Predict the last word of a Long sentence
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 12

Embedding Matrix
However, fine-tuning large models is costly, as it still requires thousands of samples to obtain good performance in a downstream task.[Ref]
Moreover, this is not how humans adapt to different tasks once they understand the language.
We can give them a book to read and "prompt" them to summarize it or find an answer for a specific question.
That is, we do not need "supervised fine-tuning" at all (for most of the tasks)
In a nutshell, we want a single model that learns to do multiple tasks with zero to a few examples (instead of thousands)!
Some tasks may not have enough labelled samples
Can we adapt a pre-trained language model for downstream tasks without any explicit supervision (called zero-shot transfer)?
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 12
Embedding Matrix
Note that, the prompts (or instructions) are words. Therefore,we just need to change the single task (LM) formulation
to multi task
where the task is just an instruction in plain words that is prepended (appended) to the input sequence during inference
Yes, with a simple tweak to the input text!
Surprisingly, this induces a model to output a task specific response for the same input
For example,
Input text: I enjoyed watching the movie transformer along with my .....
Task: summarize (or TL;DR:)
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 12
Embedding Matrix
Input text: TL;DR:
Watched the transformer movie
To get a good performance, we need to scale up both the model size and the data size
Transformer Block 1
Transformer Block 2
Transformer Block 12
Embedding Matrix
GPT with 110 Million Parameters
GPT-2 with 1.5 Billion Parameters
Layers: \(4X\)
Parameters: \(10X\)
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 48
Embedding Matrix
Dataset
A new dataset called WebText was created by crawling outbound links (with at least 3 karma) from Reddit, excluding links to Wikipedia.
This is to ensure the diversity and quality of data
Data of size 40 GB (about 8 million webpages)

naturally occurring demonstrations of English to French and French to English translation found throughout the WebText training set.
Uses Byte-Level BPE tokenizer
Vocabulary with 50,257 tokens
What about translation tasks?
Model
GPT with 4 variations in architecture
| Parameters | Layers | d_model |
|---|---|---|
| 117 M | 12 | 768 |
| 345 M | 24 | 1024 |
| 762 M | 36 | 1280 |
| 1542 | 48 | 1600 |
Context window size: 1024
Batch size: 512
Training objective : Causal Language Modeling (CLM)
Transformer Block 1
Transformer Block 2
Transformer Block 3
Transformer Block 48
Embedding Matrix
GPT-2 with 1.5 Billion Parameters
Performance on Zero-shot domain transfer
Pre-trained
(GPT-2)
Wiki-text
text8
LAMBADA
1BW
Pre-trained
(GPT-2)
Pre-trained
(GPT-2)
Pre-trained
(GPT-2)
Let's take the pre-trained (using WebText) GPT-2 large (1.5 B) model
Measure the performance of the pre-trained model on various benchmarking datasets across domains such as LM, translation,summarization, reading comprehension..
Performance on Zero-shot domain transfer
Pre-trained
(GPT-2)
Wiki-text

The model performance increases significantly upon fine-tuning
Language Modelling
Measure
Perplexity
Performance on Zero-shot domain transfer
Pre-trained
(GPT-2)
Text-8

Measure BPC
Character level language modelling
Performance on Zero-shot domain transfer
Pre-trained
(GPT-2)
LAMBADA
Open-ended cloze task which consists of about 10,000 passages from BooksCorpus where a missing target word is to be predicted in the last sentence of each passage.
Measure: Accuracy

Performance on Zero-shot domain transfer
Pre-trained
(GPT-2)
Wiki-text
text8
LAMBADA
1BW
Pre-trained
(GPT-2)
Pre-trained
(GPT-2)
Pre-trained
(GPT-2)
It outperforms other language models trained on domains like Wiki and books, without using these domain-specific training datasets
Perplexity
BPC
Accuracy
PPL
Promising direction
However, the performance of the model on tasks like question answering, reading comprehension, summarization, and translation is far from SOTA models specifically fine-tuned for these tasks.

Moreover, the 1.5 Billions parameters model still underfits the training set!
From the graph on the left, we can observe the trend that scaling the model and datasize further might give us some promising results on prompting.
This work established that "Large Language models are unsupervised multitask learners"
Module 2 : Choices that affect performance
Mitesh M. Khapra, Arun Prakash A
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
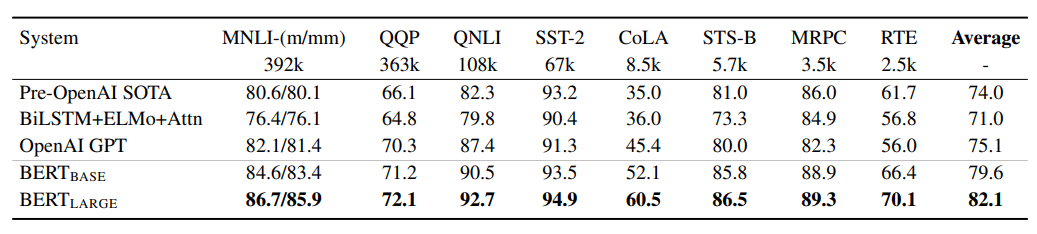
Let's compare the performance of GPT (110M) and BERT on various tasks
BookCorpusc(1 B )
WikiPedia (2.5 B)
Is it because of the size of the data set?
Books (0.7 B)
VS
Is it because of the pre-training objctive?
CLM
MLM
Why is one Model performing better than the other (in all or some tasks)?
VS
Is it because of the size of the model ( number of parameters)?
GPT
(117M)
BERT Large
(336M)
Is it because of training a model longer ?
Is it because of the way one fine-tunes the model for downstream tasks?
VS
VS
VS
GPT
(117M)
Input text
Linear layer: Learned from scratch
BERT base
(117M)
Input text
[CLS]
Linear layer is finetuned
To answer these questions, we need to conduct extensive experiments by keeping one aspect of the pipeline constant and vary the other
encoder
encoder
decoder
decoder
Scale:
- small
- medium
- large
Objective:MLM
- corruption rate
- token deletion
- span mask
Scale:
- small
- medium
- large
Scale:
- small
- medium
- large
pre-Training
pre-Training
pre-Training
Pretraining:
- Wiki
- Books
- Web Crawl
Fine-Tuning
Fine-Tuning
Fine-Tuning
FineTuning:
- GLUE
- SQUAD
- SuperGLUE
- WMT-14
- WMT-15
- WMT-16
- CNN/DM



hyp-params:
- num.of train steps
- learning rate scheme
- optimizer
hyp-params:
- num.of train steps
- learning rate scheme
- optimizer
hyp-params:
- num.of train steps
- learning rate scheme
- optimizer
Objective:
- de-noising
- corrpution rate
- continous masking
FineTuning:
- GLUE
- SQUAD
- SuperGLUE
- WMT-14
- WMT-15
- WMT-16
- CNN/DM
Objective:
- CLM
- prefix-LM
- conditional
FineTuning:
- GLUE
- SQUAD
- SuperGLUE
- WMT-14
- WMT-15
- WMT-16
- CNN/DM
Wishlist
Wishlist
Can we use a pre-training dataset which is as large as possible (to understand the effect of size of unlabelled data)
Can we have the same objective for both pre-training and fine-tuning stages?
Can we have an architecture that uses both CLM and MLM like objectives ?
Compare a variety of different approaches on a diverse set of tasks while keeping as
many factors fixed as possible.
Scale:
- small
- medium
- large
Objective:
- MLM
- CLM
- Denosing
hyp-params:
- num.of train steps
- learning rate scheme
- optimizer
Pretraining:
- Web Crawl
FineTuning:
- GLUE
- SQUAD
- SuperGLUE
- WMT-14
- WMT-15
- WMT-16
- CNN/DM
Let's do a systematic study (T5)
Idea
Formulate all NLP problems as "Text-in" and "Text-out".
Text To Text Transfer Transformer (T5)
" translate English to Tamil: I enjoyed the movie"
T5:
Encoder-Decoder Model
"summarize: state authorities
dispatched emergency crews tuesday to
survey the damage after an onslaught
of severe weather in mississippi…"
""stsb sentence1: The rhino grazed
on the grass. sentence2: A rhino
is grazing in a field.""
"3.8"
"six people hospitalized after
a storm in attala county."
" Naan padathai rasithen"
with a task-specific prefix prepended to the input context
Dataset
Colossal Clean Crawled Corpus (C4)
750 GB
Tokenizer: SentencePiece
Vocab Size: 32,000
Language: Mainly English
Number of tokens: 156 Billion (About 52 times bigger than the dataset used for pertaining BERT)

300M documents
156B tokens
Note: We will look at the details of creating such a huge dataset in the subsequent lectures

Token Distribution
Top 25 domains

Top 25 websites
Module 3 : Pre-training and finetuning a Baseline Model
Mitesh M. Khapra, Arun Prakash A
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Baseline Model
Multi-Head Attention
Feed forward NN
Add&Norm
Add&Norm
Multi-Head cross Attention
Feed forward NN
Add&Norm
Add&Norm
Multi-Head Maksed Attention
Add&Norm
\(I,<mask>, the ,movie\)
enjoyed
\(<go>\)
Encoder-decoder model allows us to experiment with all possible architectures and pre-training objectives
An encoder decoder model like BART
Baseline:
12 encoder and decoder stacks that is equivalent (in spirit) to \(BERT_{base}\) (with 12 layers).
Contains 220 million parameters (twice that of \(BERT_{base}\)parameters)
Denoising Objective
Analogous to MLM, replace a random span of tokens by a single sentinel token
What sets this <w> is the pivotal role of artificial <x> (AI) in guiding the spacecraft during its <y> to the moon's surface.
Original Text
What sets this mission apart is the pivotal role of artificial intelligence (AI) in guiding the spacecraft during its critical descent to the moon's surface.
Input Text
Target
<w> mission apart <x> intelligence <y> critical descent <z>
One advantage of this objective is that it reduces the computational cost and therefore the training time
Pre-Training
Batch size: 128
Context length: 512
What sets this <X> is the pivotal role of artificial <Y> (AI) in guiding the spacecraft during its <Z> to the moon's surface.
What sets this <X> is the pivotal role of artificial <Y> (AI) in guiding the spacecraft during its <Z> to the moon's surface.
What sets this <X> is the pivotal role of artificial <Y> (AI) in guiding the spacecraft during its <Z> to the moon's surface.
Number of tokens per batch \( \approx 512 \times 128=65,536=2^{16}\)
Number training steps = \(2^{19}=524,288\)
Total number of pre-training tokens = \(2^{19} \times 2^{16} = 2^{35}= 34 B \)
This is just a fraction of the tokens in the entire dataset (that is, we haven't even done one epoch of training!)
BERT was trained on 137 B tokens and RoBERTa was trained on 2.2 T tokens.
However, for the given compute budget and to experiment with a variety of hyperparameters, 34B tokens is a reasonable size for the baseline model
Pre-Training
What sets this <X> is the pivotal role of artificial <Y> (AI) in guiding the spacecraft during its <Z> to the moon's surface.
What sets this <X> is the pivotal role of artificial <Y> (AI) in guiding the spacecraft during its <Z> to the moon's surface.
What sets this <X> is the pivotal role of artificial <Y> (AI) in guiding the spacecraft during its <Z> to the moon's surface.
Optimizer: AdaFactor (requires less memory storage than Adam)
Learning rate schedulater: inverse square root scheduler (\(\frac{1}{\sqrt{max(n,k)}}\)), where \(n\) is training step and \(k\) is warm-up steps which is set to \(10^4\)
Batch size: 128
Context length: 512
Number of tokens per batch* \( 512 \times 128=65,536=2^{16}\)
Number training steps = \(2^{19}=524,288\)
Total number of pre-training tokens = \(2^{19} \times 2^{16} = 2^{35}= 34 B \)
* during fine-tuning we use same number of tokens but keep B=512, T=128
C4 Dataset
\(BERT_{base}\) Like enc-dec with 220M parameters
Denoising objective
pre-training
steps
\(\approx 34B\) tokens
GLUE
SuperGLUE
CNN/DM
SQuAD
WMT16 EnRo
steps*
\(\approx 17B\) tokens
Fine-tuning
GLUE and SuperGLUE : Collection of tasks (datasets) to train and test natural language understanding.
CoLA
SST
STSB
MNLI
RTE
For text summarization.
For Question Answering
For Translation
report an average score (as defined by the authors of GLUE)
* a trade-off between high resource tasks (benefit from longer fine tuning) and low resource tasks (overfits)
\(\eta=0.001\)
C4 Dataset
\(BERT_{base}\) Like enc-dec with 220M parameters
Denoising objective
pre-training
steps
\(\approx 34B\) tokens
GLUE
SuperGLUE
CNN/DM
SQuAD
WMT16 EnRo
steps
\(\approx 17B\) tokens
Fine-tuning
Evalaute on Validation
Choose the best
model parameters for reporting the performance
in the subsequent slides dentoes the baseline model
Step 810000
Step 800000
Step 790000
Step 780000
Performance

Pre-train and fine-tune the baseline model 10 times from scratch (to compute average) with different initialization and data shuffling
Also, train the baseline model directly on the benchmarking datasets for \(2^{18}\) steps (the same number of steps used for fine-tuning)
Unsurprisingly, pre-training helps improve the model performance for small sized datasets across a variety of tasks
Supervised training with big dataset has a slight edge over pre-training as in the case of English-to-French translation
Baseline model Performance
The \(BERT_{base}\) model achieved 80.8 on SQuAD dataset and 84.4 on MNLI dataset
Note, however, that we cannot directly compare the performance of \(BERT_{base}\) with the basline model as the architecture, number of parameters were different and \(BERT_{base}\) was trained on \(137B\) tokens whereas baseline model was trained on 37B tokens
Whereas the baseline model achieved 80.88 on SQuAD and 84.24 on MNLI
Therefore, for the given task, we need a way to compare different architectures
Module 4 : Experimenting with different Architectures
Mitesh M. Khapra, Arun Prakash A
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
The diagram on the right shows three architectural variants that are under study
Denoising (MLM)
CLM
Prefix - LM
The prefix language modelling objective was also used to pre-train a model under a unifying text-to-text framework [paper]

Schematics

Mask Patterns
Let's take a closer look at prefix LM
Dark cells: Self-attention allowed
Light cells: Self-attention not allowed
Prefix-Language Modelling
summarize the following: I enjoyed watching the transformer movie along with my .....
Consider the following task specific input
In prefix language modelling, we want the input sequence to be attended bidirectionaly and the task output sequence autoregressively

Therefore, we can use the encoder for the input sequence and decoder for the output sequence
We can also use the decoder with the prefix-mask instead of causal mask by pre-pending the task to the input sequence
While pre-training on C4, we can take a random span of text and randomly split the text into two portions one for prefix and the other for target
Parameters and FLOPS
we need to show that the models are equivalent in some meaningful way.
One possible criterion is to choose the number of parameters \(P\) in a model
Another criterion is to use the amount of compute \(M\) (in FLOPS) required to process an input and target sequences
an encoder-decoder model with \(L\) layers in the encoder and \(L\) layers in the decoder has approximately the same number of parameters as a language model with \(2L\) layers
However, we can't use both these criteria at the same time to compare the models. Let's see why..
whereas the computational cost of both models is the same for the given input sequence and task
How?
take it as an exercise problem :-) !
The baseline model uses enc-dec architecture. How do we compare it with encoder only or decoder only models?
encoder
decoder
decoder
decoder

Performance
\(P\): Number of parameters in the \(BERT_{base}\) model (not the baseline)
\(M\): Number of FLOPS for \(L+L\) layer enc-dec model or \(L\) layer dec only model
The first row is for the baseline model which contains twice the number of parameters as compared to the \(BERT_{base}\) model
12 x encoder
12 x decoder
Performance
A slight decrease in performance due to parameter sharing!
12 x encoder
12 x decoder
\(P\): Number of parameters in the \(BERT_{base}\) model (not the baseline)
\(M\): Number of FLOPS for \(L+L\) layer enc-dec model or \(L\) layer dec only model
The first row is for the baseline model which contains twice the number of parameters as compared to the \(BERT_{base}\) model
Performance
Decreasing number of layers degrades the performance on downstream tasks
6 x encoder
6 x decoder
\(P\): Number of parameters in the \(BERT_{base}\) model (not the baseline)
\(M\): Number of FLOPS for \(L+L\) layer enc-dec model or \(L\) layer dec only model
The first row is for the baseline model which contains twice the number of parameters as compared to the \(BERT_{base}\) model
Performance
For fixed \(P\) and \(M\), Enc-dec model performs well
12 x decoder
\(P\): Number of parameters in the \(BERT_{base}\) model (not the baseline)
\(M\): Number of FLOPS for \(L+L\) layer enc-dec model or \(L\) layer dec only model
The first row is for the baseline model which contains twice the number of parameters as compared to the \(BERT_{base}\) model
than the language model
Performance
12 x decoder
What if we change the objective?
For fixed \(P\) and \(M\), the performance of the decoder only model with Prefix LM is similar to enc-dec model.
\(P\): Number of parameters in the \(BERT_{base}\) model (not the baseline)
\(M\): Number of FLOPS for \(L+L\) layer enc-dec model or \(L\) layer dec only model
The first row is for the baseline model which contains twice the number of parameters as compared to the \(BERT_{base}\) model

denoising objective always results in better downstream task performance compared to language modeling objective.
Let's take a closer look at different unsupervised objectives
\(P\): Number of parameters in the \(BERT_{base}\) model (not the baseline)
\(M\): Number of FLOPS for \(L+L\) layer enc-dec model or \(L\) layer dec only model
The first row is for the baseline model which contains twice the number of parameters to \(BERT_{base}\) model
Module 4.1 : Effect of Unsupervised Objectives
Mitesh M. Khapra, Arun Prakash A
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Language
Modelling
BERT-Style
Deshuffling
Unsupervised Objectives
Let's see an example (input,target) sequence for each type
| Objective | Inputs | Targets |
|---|---|---|
| Prefix language modeling | Thank you for inviting | me to your party last week . |
| BERT-style* | Thank you for <M> me to <M> party apple week . | (original text) |
*this is slightly different from original BERT objective where we only predict masked tokens
** MASS-style is similar to BERT-style without random replacement of tokens
| Deshuffling | party me for your to . last fun you inviting week Thank | (original text) |
| Random spans | Thank you <X> to <Y> week . | <X> for inviting me <Y> your party last <Z> |
| MAsked Seq-to-Seq pretraining (MASS)** | Thank you <M> <M> me to your party <M>week . | (original text) |
Input text: " Thank you for inviting me to you party last week"
Language
Modelling
BERT-Style
Deshuffling
Exploring unsupervised objectives
high-level
objectives
Overall, a BERT-style objective is better!

Both prefix-LM and BERT-style objectives are better at translation tasks!
Deshuffling objective is worse!
There are other ways of corrupting the input sequence such as, continuous masking, replace random span of text, dropping tokens
Which of these approaches for corrupting tokens is better? Let's see
| Thank you <M> <M> me to your party apple week . |
Language
Modelling
BERT-Style
Deshuffling
Mask
Replace Tokens
Drop
More knobs to tune
corruption
strategies
high-level
objectives

All these variants perform similarly.
"Dropping corrupted tokens" leads to a slightly better performance on GLUE (because it performed well on one of the subtasks "CoLA") but worse on SuperGLUE
Overall, replacing corrupted span of tokens by a sentinel token performs well
Well, what is a good corruption rate then?
| Thank you <X> to <Y> week . | <X> for inviting me <Y> your party last <Z> |
Language
Modelling
BERT-Style
Deshuffling
Mask
Replace Tokens
Drop
10%
15%
25%
50%
corruption
stratagies
corruption
rate
Corruption rate has minimal effect on performance!

high-level
objectives
| Thank you for inviting <X> to your party last week . | <X> me <Z> |
| Thank you for inviting <X> to your party<Y>week . | <X> me <Y>Last <Z> |
| Thank you for inviting <X> to your <Y>week . | <X> me <Y>party last <Z> |
| Thank you <X> to your <Y>week . | <X>for inviting me <Y>party last <Z> |
But, what about the span length?
Language
Modelling
BERT-Style
Deshuffling
Mask
Replace Tokens
Drop
10%
15%
25%
50%
2
3
5
10
corruption
stratagies
corruption
rate
corrupted span length

A little difference in performance (except for 10 that underperforms in two tasks)
high-level
objectives
Span length of 3 outperforms others in non-translation tasks
Module 4.2 : Effect of Size of the pre-training dataset
Mitesh M. Khapra, Arun Prakash A
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Pre-training Dataset
Do the scale and quality of the pre-training dataset determine the model's performance in downstream tasks?

Let's start with the C4 (clean/filtered) dataset used for training the baseline model
Pre-training Dataset
Unfiltered-C4: Apply only language detection filtering. No other filtering such as dedpulication, removing bad words and so on
Note the scale of the dataset (almost 8 times bigger than C4)
The performance degraded across all tasks despite a large increase in the scale of the dataset!
Pre-training Dataset
RealNews-like: Build a dataset similar to "RealNews" pre-training dataset by filtering C4 dataset that comes from the news website
The scale of the dataset is almost 21 times smaller than C4
Despite the size, it performs well across many tasks.
Quality is important for good performance!
Let's scale it down further
Pre-training Dataset
These datasets are almost 42 times smaller than C4
WebText-like: Build a dataset similar to "WebText"
Wikipedia: A pre-trainig dataset used in GPT
Wikipedia+BookCorpus: A pre-trainig dataset used in BERT
Key take away: pre-training on in-domain unlabeled data can improve performance on downstream tasks
Do we need to use 156 Billion tokens for pre-training ?
Moreover, the baseline model was trained only on a fraction (34B) of the C4 dataset. ( that is, model has seen a training sample in the dataset only once)
Would repeating examples during pre-training be helpful or harmful for downstream performance?
Some questions to ponder about

To study this , we can vary the size of the dataset having number of tokens from \(2^{23}\) to \( 2^{29}\)

The baseline model was trained on \(2^{35}=34B\) tokens. (Refer to that as Full dataset)
Repeat the training \(2^{6}=64\) times, so that the model would have seen same \(2^{35}=2^{29} \times 2^{6}\) tokens with repeating training examples.
A slight degradation in performance across multiple tasks (except SQuAD and SGLUE)
The baseline model was trained on \(2^{35}=34B\) tokens. (Refer to that as Full dataset)
Repeat the training \(2^{8}=256\) times, so that the model would have seen same \(2^{35}=2^{27} \times 2^{8}\) tokens with repeating training examples.
Let's go further
The model performance degrades (as expected)!
The model might have memorized the pre-training dataset.
How do we validate that?
Plot the training loss..
Repeat the training \(2^{8}=256\) times, so that the model would have seen same \(2^{35}=2^{27} \times 2^{8}\) tokens with repeating training examples.
Let's go further

As expected, pre-training a large model for more epochs with a small dataset leads to memorization
Takeaway: Scaling the pre-training dataset might scale the performance on the downstream tasks.
Module 5 : Fine-Tuning Strategies
Mitesh M. Khapra, Arun Prakash A
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
T5
Enc-Dec
T5
Enc-Dec
Fine-tuning
Standford Sentiment Tree Bank (SST)
SNLI
C4 Dataset
\(BERT_{base}\) Like enc-dec with 220M parameters
Denoising objective
pre-training
steps
steps
Fine-tuning all parameters in the model is computationally expensive
Fine tuning methods
Let's consider other alternatives (to reduce the computational cost)
Adaptive Layers
Add an adapter layer after FFN block in each layer

Adaptive Layers
Add an adapter layer after FFN block in each layer

It is simply a \(dense-ReLU-dense\) layer with inner dimension \(d\) with the residual connection
The number of paramters in the adapter layer is typically 0.5 to 8 % of parameters in the transformer layer
During fine-tuning only the adapter layers and layer normalization parameters are updated
We can vary the size of \(d\) and its performance on downstream tasks

Lower value of \(d\) is fine for lower-resource tasks like SQuAD (worse for other tasks)
Higher resource tasks require a larger value of \(d\) to achieve reasonable performance
Let us now look at another fine tuning approach called "gradual unfreezing"
Gradual Unfreezing
Encoder
Decoder
Freeze the parameters of all the layers
Gradually unfreeze the parameters in the layers starting from the top (12th) layer
Gradual Unfreezing
Encoder
Decoder
Fine tuning steps: \(2^{18}\)
Number of layers: 12 each
Therefore, there will be 12 episodes of unfreezing.
Freeze the parameters of all the layers
Gradually unfreeze the parameters in the layers starting from the top (12th) layer
Unfreezing happens simultaneously for the \(k\)-th layer of encoder and decoder
Unfreezing happens for every \(\frac{2^{18}}{12}\) steps starting from top layer
Causes a slight degradation in performance
Speeds up the training process
Better results may be attainable by more carefully tuning the unfreezing schedule
Module 6 : Multi-task Learning
Mitesh M. Khapra, Arun Prakash A
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Motivation
C4 Dataset
\(BERT_{base}\) Like enc-dec with 220M parameters
Denoising objective
pre-training
steps
GLUE
SuperGLUE
CNN/DM
SQuAD
WMT16 EnRo
steps
Fine-tuning
Earlier we fintuned the pre-trained model inpendently on all the downstream tasks
It is observed that adding more quality data is helpful for better downstream performance
Why not use the datasets from all supervised learning tasks for pre-training
Under this T5 framework, this corresponds to mixing datasets together and jointly training (instead of using a separate loss functions for each task)
" translate English to Tamil: I enjoyed the movie"
T5:
Encoder-Decoder Model
"summarize: state authorities
dispatched emergency crews tuesday to
survey the damage after an onslaught
of severe weather in mississippi…"
""stsb sentence1: The rhino grazed
on the grass. sentence2: A rhino
is grazing in a field.""
"3.8"
"six people hospitalized after
a storm in attala county."
" Naan padathai rasithen"
Multi-task Learning
The unified T5 framework allows us to pre-train and/or fine-tune a single model for all tasks
General Multi-task Learning
C4 Dataset
\(BERT_{base}\) Like enc-dec with 220M parameters
Denoising objective
multi-task training
steps
GLUE
SGLUE
CNN/DM
SQuAD
WMT16 EnRo
train for
However, the dataset size for all the tasks may not be uniform
Therefore, it is important to use some sampling strategy to avoid favouring performance on one task over other
Let \(K\) be an artificial limit to the size of datasets. Say we have \(N\) tasks and original number of samples in each task is
Examples-Proportional Mixing
We can form a new dataset by simply concatenating all datasets (both labelled and unlabelled)
then the probability of seeing a sample from the \(m-\)th task during training is
C4 Dataset
GLUE
SGLUE
CNN/DM
SQuAD
WMT16 EnRo
Sampler
\(r_m\)

Temperature Mixing
Use \((r_m)^{\frac{1}{T}}\), where (\(T\)) is a temperature parameter
similar to the approach we followed for softmax
For higher values of \(T\), the distribution becomes uniform
For lower values of \(T\), the distribution becomes skewed
Performance

There is a sweet spot for the value of \(K\) that works better for some tasks
Neither increasing the value of \(K\)(size of limited dataset) nor decreasing it helps much
Temperature \(T=2\) works better for some tasks
In general, Multi-task training degrades performance than pre-train-then-fine-tune approach
Multi-task Learning with Fine-Tuning
C4 Dataset
\(BERT_{base}\) Like enc-dec with 220M parameters
Denoising objective
multi-task pre-training
steps
GLUE
SGLUE
CNN/DM
SQuAD
WMT16 EnRo
Joint Fine-tuning
steps
Pre-training with example proportional mixing with \(K=2^{19}\)
GLUE
SuperGLUE
CNN/DM
SQuAD
WMT16 EnRo
Relaxed Multi-task Learning with Fine tuning
C4 Dataset
\(BERT_{base}\) Like enc-dec with 220M parameters
Denoising objective
GLUE
SGLUE
CNN/DM
SQuAD
WMT16 EnRo
Take Best checkpoints for each task
multi-task pre-training
Take the best checkpoints for each task for reporting the performance
steps
steps
Joint Fine-tuning
GLUE
SuperGLUE
CNN/DM
SQuAD
WMT16 EnRo
Three Variants
C4 Dataset
GLUE
SGLUE
CNN/DM
SQuAD
WMT16 EnRo
Multi-task pretraining (use all datasets),
EP Sampling, \(K=2^{19}\)
pre-training
Fine-tuning
Leave-one-out pretraining, (repeat for all tasks)
EP Sampling, \(K=2^{19}\)
SQuAD
CNN/DM
steps
steps
EP: (Examples-Proportional)
GLUE
SGLUE
CNN/DM
SQuAD
WMT16 EnRo
C4 Dataset
GLUE
SGLUE
CNN/DM
SQuAD
WMT16 EnRo
C4 Dataset
GLUE
SGLUE
CNN/DM
SQuAD
WMT16 EnRo
Simulates the real world where a pre-trained model is fine-tuned on a task it had not seen during pre-training
Three Variants
steps
steps
C4 Dataset
GLUE
SGLUE
CNN/DM
SQuAD
WMT16 EnRo
Multi-task pretraining (use all datasets),
EP Sampling, \(K=2^{19}\)
pre-training
Fine-tuning
GLUE
SGLUE
CNN/DM
SQuAD
WMT16 EnRo
Leave-one-out pretraining, (repeat for all tasks)
EP Sampling, \(K=2^{19}\)
C4 Dataset
GLUE
SGLUE
CNN/DM
SQuAD
WMT16 EnRo
SQuAD
Supervised pretraining,
EP Sampling, \(K=2^{19}\)
GLUE
SGLUE
CNN/DM
SQuAD
WMT16 EnRo
C4 Dataset
EP (Examples-Proportional)
GLUE
SGLUE
CNN/DM
SQuAD
WMT16 EnRo

Fine-tuning after multi-task pre-training results in comparable performance to our baseline
The performance of "leave-one-out” training was only slightly worse (suggesting that a model that was trained on a variety of tasks can still adapt to new tasks)
Supervised multitask pre-training helps only in translation tasks (english pre-training does not help much)
Unsupervised pre-training+finetuning still dominates other approaches because it was trained on \(2^{34}\) tokens!
Module 7 : What do you do if you have more compute budget?
Mitesh M. Khapra, Arun Prakash A
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
It is well known that scaling the parameters of the model improves the performance, so we may go from \(BERT_{base}\)-like to \(BERT_{large}\)-like, by increasing number of layers, attention heads, \(d_{model}\), \(d_{ff}\)..
By using ensemble techniques (ensemble of 4 separately pre-trained and fine-tuned models)
Suppose you are given \(4\times \) more compute budget, how do you use that to scale the model?
Aggregate
Train the model for longer (allows the model to see more tokens, still a fraction of full dataset)

Increase the batch size (allows the model to see more tokens, for the same \(2^{19}\) time steps)
Baseline
Baseline
Baseline
Baseline
\(128\)
\(512\)
Baseline
\(2 \times\)
\(4 \times\)

Increasing the training time (batch size) consistently improves the baseline (not a surprise)
Now, increase the model size \(2\times\) and limit the training steps to \(2t\) (that is model sees less number of tokens than the previous case)
Increasing the training time (batch size) consistently improves the baseline (not a surprise)
Now, increase the model size \(2\times\) and limit the training steps to \(2t\) (that is model sees less number of tokens than the previous case)
Scaling the number of parameters (at the cost of reduced time steps) gives better performance in many tasks!
Increasing the training time (batch size) consistently improves the baseline (not a surprise)
Now, increase the model size \(2\times\) and limit the training steps to \(2t\) (that is model sees less number of tokesn than the previous case)
Scaling the number of parameters (at the cost of reduced time steps) gives better performance in many tasks!
Ensembling also gives a resonable performance across many tasks (especially translation tasks)
So, what is better: scaling parameters or training steps?
It is a trade-off that we need to make
For example, scaling the number of parameters requires more compute during fine-tuning and leads to a larger inference time
Pushing the Limits: Large Language Models
After this extensive study the authors made the following design choices for T5 model
Architecture: Encoder-Decoder
Objective: Denoising with span corruption
Pre-training Dataset: C4
Training strategy: Multi-task Pre-training
Model size: Bigger the better
Training steps: Longer the better
They train models of different sizes as shown in the table
We also now know that pre-training for larger number of steps and increasing batch size helps improving performance
Therefore, all these models were pre-trained for 1 million steps (\(2^{20}\)) with the batch size of 2048 (\(2^{11}\) sequences of length 512)
This corresponds to the model seeing 1 Trillion tokens (32 times higher than the baseline)
Well, with all these settings, we would expect to get SOTA on many tasks.
| Model | layers | heads | ||||
|---|---|---|---|---|---|---|
| Small | 60M | 6 | 512 | 2048 | 64 | 8 |
| Base | 220M | 12 | 768 | 3072 | 64 | 12 |
| Large | 770M | 24 | 1024 | 4096 | 64 | 16 |
| 3B | 3B | 24 | 1024 | 16384 | 128 | 32 |
| 11B | 11B | 24 | 1024 | 65536 | 128 | 128 |
Performance




