Challenges in Building and Evaluating Indic LLMs


Mitesh M. Khapra, Arun Prakash A
Assumption:
There may be different types of participants

some just starting with ML

others already building cool stuff


a few at the forefront of advancements
entropy
Three stages of Building LLMs

Building Benchmarks for Evaluation
Building Dense-or-sparse Model
Building Pre-and-post Training Dataset

Fuel efficiency should not depend on the state where you refuel.
Three stages of Building LLMs
Building Benchmarks for Evaluation
Building Dense-or-sparse Model
Building Pre-and-post Training Dataset
BookCorpus
OpenWebText
C4
CC-Stories
FLAN
BigQuery
The Pile
Alpaca
REALNEWS
CC-NEWS
StarCoder
RedPajama
DOLMA
WikiPedia
Dolly
Three stages of Building LLMs
Building Benchmarks for Evaluation
Building Dense-or-sparse Model
Building Pre-and-post Training Dataset
Palm
LLaMa x
Gemini
Claude
DeepSeek
Grok
Qwen
Mistral
Gemma-x
Phi-4
GPT 4x
BLOOM
Three stages of Building LLMs
Building Benchmarks for Evaluation
Building Dense-or-sparse Model
Building Pre-and-post Training Dataset
Squad
GLUE
SuperGLUE
HELM
MMLU
MMLU-PRO
BIG-Bench
DOVE
WInoGrande
HellaSwag
Indic LLMs
Building (Indic) Benchmarks for Evaluation
Building or (Continual training) Dense-or-sparse Model
Building (Indic) Pre-and-post Training Dataset
We have challenges to address at each stage
Poll: Which stage would you like to work on?
Some challenge, esspecially in evals, is common for all languages
Challange:
Everyone wants to do the model work, not the data work*
Building Benchmarks for Evaluation
Training Dense-or-sparse Model
Building Pre-and-post Training Dataset

Data work seems less attractive and rewarding !
Training a model seems rewarding !
However, improved real-world performance of model depends on the quality of data
Collecting high quality data in Indian Languages is a huge undetaking !
Need in-house data annotation team
C4
ROOTS
DOLMA
mC4
Dataset Name
# of tokens
~156 Billion
Diversity
Webpage
~170 Billion
22 sources
> 1 Trillion
380 Programing languages
5 Trillion (600B in public)
Webpage
1.2/30 Trillion
Webpage, Books, Arxiv, Wiki, StackExch
3 Trillion
Webpage, Books, Wiki, The Stack, STEM
~418 Billion
Webpage
~341 Billion
natural and programming languages
Languages
English
English
Code
English
English/Multi
English
Multi
Multi
Effort by AI4Bharat
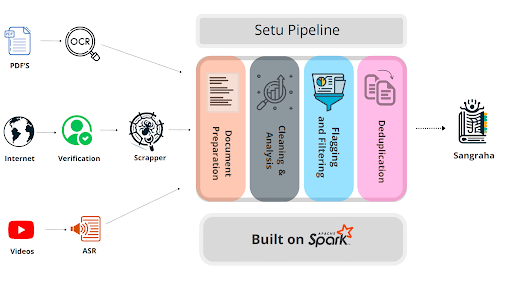


English data
Capture all India specific knowledge in all Indian Languages!
C4
ROOTS
DOLMA
mC4
Sangraha
Dataset Name
# of tokens
~156 Billion
Diversity
Webpage
~170 Billion
22 sources
> 1 Trillion
380 Programing languages
5 Trillion (600B in public)
Webpage
1.2/30 Trillion
Webpage, Books, Arxiv, Wiki, StackExch
3 Trillion
Webpage, Books, Wiki, The Stack, STEM
~418 Billion
Webpage
~341 Billion
natural and programming languages
251 Billion
Web, videos, digitized pdf,synthetic
Languages
English
English
Code
English
English/Multi
English
Multi
Multi
Multi
Challenge:
Training is no longer task specific
\(D_{train}(x,y)\)
Model
\(\hat{y}\)
Generative models are trained to learn the world knowledge
What does that mean?
Then expected to generalize across tasks

Magic Box




Creative Text Generation
"Any sufficiently Advanced Technology is Indistinguishable from Magic"

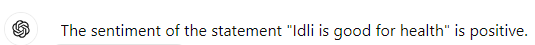
Simple Sentiment Classification
Magic Box
"Any sufficiently Advanced Technology is Indistinguishable from Magic"

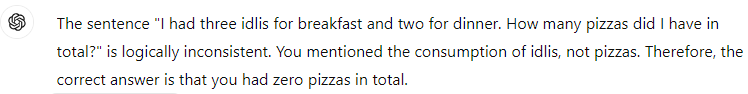
Logical Reasoning
Magic Box
"Any sufficiently Advanced Technology is Indistinguishable from Magic"
Doing arithmetic


Magic Box
"Any sufficiently Advanced Technology is Indistinguishable from Magic"

Magic Box

"Any sufficiently Advanced Technology is indistinguishable from Magic"
Magic Box
Multi-head Masked Attention
N \times
tell
me
a
joke
about
idli

\leftarrow prompt \rightarrow
\leftarrow response \rightarrow
\leftarrow prompt \rightarrow
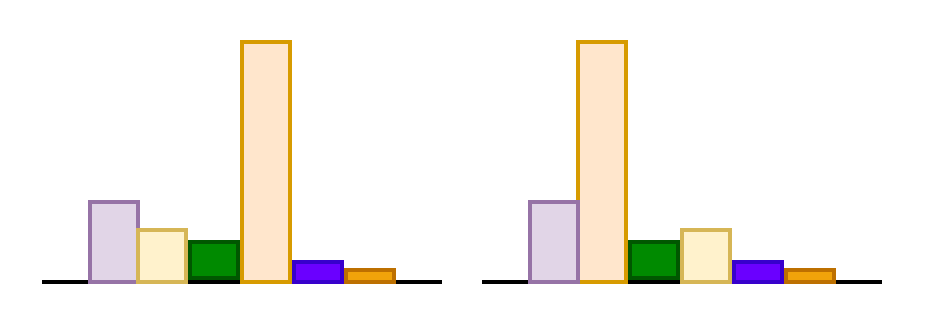

W_v
why
why
W_v
W_v
did
the
did
\leftarrow response \rightarrow
\cdots
\cdots
Multi-head Masked Attention
tell
me
a
joke
about
idli
W_v
why
why
W_v
W_v
did
the
did
\cdots
\cdots
The Magic:
Train the models to predict next word given all previous words
W_v
idli
the
“The magician takes the ordinary something and makes it do something extraordinary.”

Traditional NLP Models
Large Language Models
Input text
Predict the class/sentiment
Input text
Summarize
Question
Answer
Input text
LLMs
Prompt: Input text
Output response conditioned on prompt
Prompt: Predict sentiment, summarize, fill in the blank, generate story
Labelled data for task-1
Labelled data for task-2
Labelled data for task-3



Raw text data
(cleaned)
Model-1
Model-2
Model-3





Trillions of
Tokens
Billions of
Parameters
Zetta FLOPS
of Compute
LLMs
+
+
Three Stages
Pre-training
Fine tuning
Inference
Trident of LLMs
Trillions of Tokens
LLMs
W_v
Next token
“The magician takes the ordinary something and makes it do something extraordinary.”
Something Ordinary:
To Extraordinary:
Predict next token
and next token, next token, .........
Sourcing billions of tokens from the Internet is a massive engineering effort!!
Pre-Training
By doing this, the model eventually learns language structure, grammar and world knowledge !
Way to go: Language Adaptation ?
Trillions of
Tokens
Billions of
Parameters
Zetta FLOPS
of Compute
Pre-Trained open sourced LLM
+
+

Way to go: Language Adaptation ?
Trillions of
Tokens
Billions of
Parameters
Zetta FLOPS
of Compute
Pre-Trained open sourced LLM
+
+
Billions of
Tokens
Billions of
Parameters
Peta FLOPS
of Compute
Fully fine-tuned
+
+
Sangraha
Billions of
Parameters





Fruit Fly
Honey Bee
Mouse
Cat
Brain
>10^6
10^9
10^{12}
10^{13}
10^{15}
# Synapses
400M
Transformer
1.5B
GPT-2
10B
Megatron LM
175B
GPT-3
GShard
1.1 T
1.6 T
Affordable for inference
Opportunity:
Use Instruction Fine-tuning and build datasets for the same
Challenge:
(full) Fine-Tuning of LLMs on Indic datasets still requires a lot of compute and expensive
Way to go: Instruction Fine-Tuning
Millions of
Tokens
Billions of
Parameters
Tera FLOPS
of Compute
Instruction-tuned
+
+
Indic-Align
Goal:
Improve the model’s ability to understand and follow human instructions and ensure response is aligned with human expectations and values.
How it works:
Training the model on a set (relatively small) of high quality and diverse instruction and answer pairs.
How do we source the data?





From all the places where a conversation happens!
100 K
52K
64K
84K
<10K
500 K
Alpaca
Unnatural
Self-Instruct
143K
Evolved Instruct
What should be the size?
1M
10M
534K
Guanaco
620K
Natural Inst
1.5M
Ultra Chat
12M
P3
15M
FLAN
Significantly lesser
But more high quality!!
For Indian Languages ?


Existing English Data
Synthetic India-centric conversations

Indic-Align

Capture all different ways in which people can ask!!
Challenge:
Evaluation
How do we compare the performance of one model to the other?
How good is the model at solving a given task?
Are there any more hidden skills we dont know about?
How good is the model in other languages?
Is the model biased? Is it Toxic? Is it Harmful?


There are hundreds of models in the market (ChatGPT, Llama, Gemma, Sutra ..)

Evaluating Generative Model's capabilities is much much harder than traditional models
TL;DR
You test it!

What are you capable of, Genie?
What are you capable of, GPT?
You test it!
Generative Model's undermines the traditional benchmarks such as GLUE, SuperGLUE,..
It is highly challenging to build benchmarks to evaluate open-ended models
We are still in a nascent stage


May 2024
March 2025

April 2025
Three Components of Evaluation
Models
Tasks/Scenarios





GPT 4x
LLaMa x
Gemini
Claude
DeepSeek
Grok
Qwen
Mistral
Gemma
Phi-4
Question Answering
Summarization
Translation
Token classificaiton
Text
Classification
Text Generation
Entailement
Safety
Metrics
\degree C
K
\degree F
Accuracy
BLEU
ROUGE
Exact Match
Helpfulness
Fairness
BPC, BPB
Three Approaches to Evaluation
Automatic Evaluation
Human/Expert Evaluation
AI as Judge
Input text
Pre-Trained
Model
Generated Text
Ground Truth/ Reference
Performance Metrics (acc, f1, ..)
Input text
Pre-Trained
Model
Generated Text
Performance Metrics (ranking, rating)

Input text
Pre-Trained
Model
Generated Text
Performance Metrics (ranking, rating)

Ever-Evolving Evalaution Benchmarks
2016
2017
2018
2019
2020
2021
2022
2024
Lambada
sentence
completion
AI2 ARC
QA Systems
(custom)
BERT
Finetuning
GPT-2
Prompting
GPT-3
In-context Learning
Chat GPT
Chat Format
OBQA
QA Systems
(custom)
HellaSwag
Fine-Tuning
WinoGrande
Fine-Tuning
MMLU
In-context Learning
MATH
FT, ICL
BIG Bench
FT, ICL
Omni-Math
FT, ICL
MMLU-Pro
FT, ICL
Ever-Evolving Evalaution Benchmarks
2016
2017
2018
2019
2020
2021
2022
2024
Lambada
sentence
completion
AI2 ARC
QA Systems
(custom)
BERT
Finetuning
GPT-2
Prompting
GPT-3
In-context Learning
Chat GPT
Chat Format
OBQA
QA Systems
(custom)
HellaSwag
Fine-Tuning
WinoGrande
Fine-Tuning
MMLU
In-context Learning
MATH
FT, ICL
BIG Bench
FT, ICL
Omni-Math
FT, ICL

Exponential increase in newbenchmarks over the past three years
MMLU-Pro
FT, ICL
Characteristics of Benchmarks
Ideal benchmarks should evaluate a range of tasks that covers all capabilities of LLMs
You test it!
What are you capable of, Genie?

Ok, let us try our best!
Choosing between Open-Ended vs Close-Ended format

We can evaluate the model's knowledge across different domains in two ways
We can simply ask the question from a specific domain and evaluate its response (open-ended format)
However, it is very difficult to automate the evaluation process
Which financial institutions in India offer 15% interest for Fixed Depoist?
Correct Answer: No financial institutions in India offer 15% return for a Fixed Depoist
Correct Answer: National banks such as SBI,ICICI,HFDC and KVB offers only 5% to 7% interest for FD
Correct Answer: None
Choosing between Open-Ended vs Close-Ended format
The easiest approach is to reframe the question in MCQ format
In this case, automating the evaluation process is simple
Which of the follwing financial institutions in India offer 15% interest for Fixed Depoist?
A. SBI
B. HDFC
C. IDBI
D. None of the above
Correct option: D
To evaluate various capabilties (domain knowledge, factualness..), one can use MCQ format when possible
Massive Multitask Language Understanding (MMLU)
MMLU is composed of 57 tasks that are grouped into four major categories: Humanities, STEM, Social Sciences and others
It contains about 15908 MCQ questions, with at least 100 questions for each task (a reasonable size for evaluating human performance)
Here is a sample question from the dataset (give it a try :-))

In the complex z-plane, the set of points satisfying the equation \(z^2=|z|^2\) is a
(A) Pair of points
(B) Circle
(C) Half-line
(D) Line
The question and the options are given as a prompt to the model and the model generates a probability distribution for all the tokens in the vocabulary (that is, predicting the next token)
Large Language Model
Question: In the complex z-plane, the set of points satisfying the equation \(z^2=|z|^2\) is a
Choices:
(A) Pair of points
(B) Circle
(C) Half-line
(D) Line
Correct answer :
| A |
| an |
| apple |
| book |
| B |
| cup |
| C |
\vdots
| A |
| B |
| C |
| D |
The maximum of probabilities of tokens A, B, C, and D are considered ( ignoring the probabilities of other tokens) as the model's prediction
C is a Wrong Prediction
Predicting from Text Continuation
We can use accuracy as a metric ( as MCQ is like a classification with the options (for example: positive, neutral, negative) remaining the same for all questions.)
Compute average (or weighted) accuracy across all tasks
Evalauting generative models is a different game than traditional NLP models
Assume that we have a model A ,and three teams checked the model's performance on the MMLU benchmark
Team 1 reports 55% accuracy
Team 2 reports 45% accuracy
Team 3 reports 65% accuracy
All the teams disclosed that they haven't fine-tuned the model on any auxilary data.
If there is no change in parameters, then what could be the trick used by Team 3?
Change in the format of the Prompt?
Change in number of demonstrations (one-shot, few-shot,..)?
or combination of these? What else?
Let's see how change in prompt changes model performance
Passage:<text>
Answer:
PASSAGE:<text>
ANSWER:
Passage:<text> Answer:
Passage:<text>
Answer: A
Passage:<text>
Answer:
Passage:<text>
Answer: A
Passage:<text>
Answer: B
Passage:<text>
Answer:
Here is the performance of microsoft's phi-4 instruction tuned model on MMLU benchmark
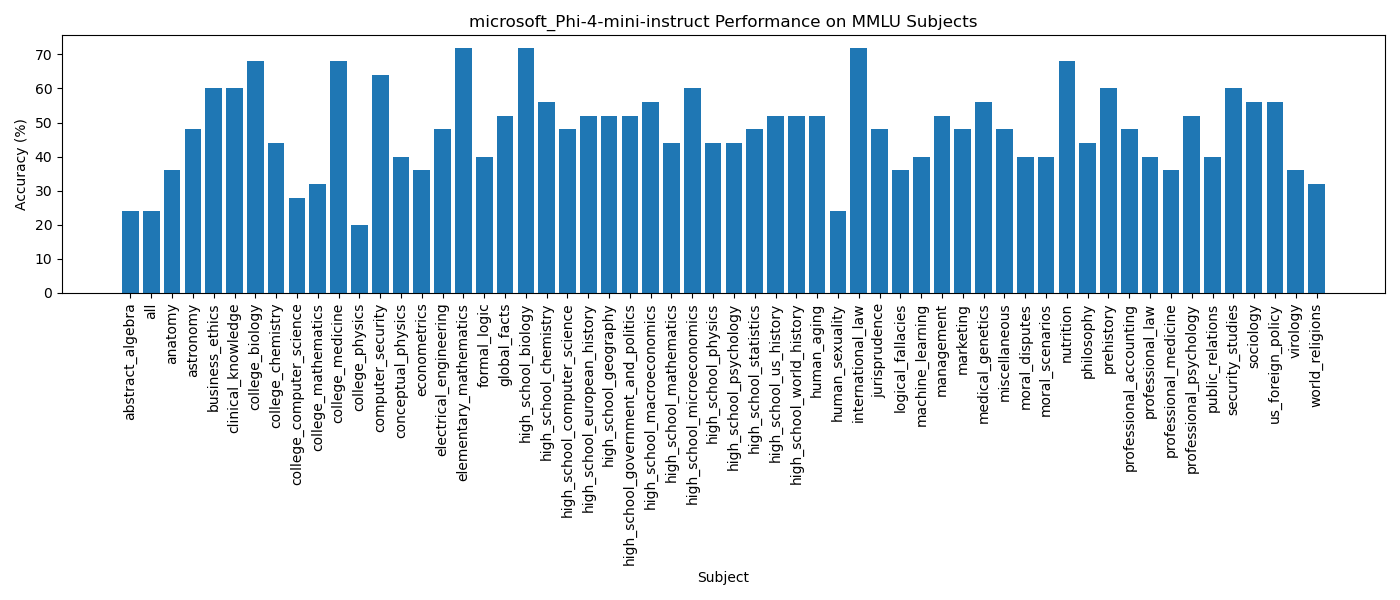
Prompt: f"Here is the question and the four choices{question,choices}. Choose the correct optionAccuracy "all" = 25%
Here is the performance of microsoft's phi-4 instruction tuned model on MMLU benchmark
prompt: f"Q: {question}\n Choices:\n "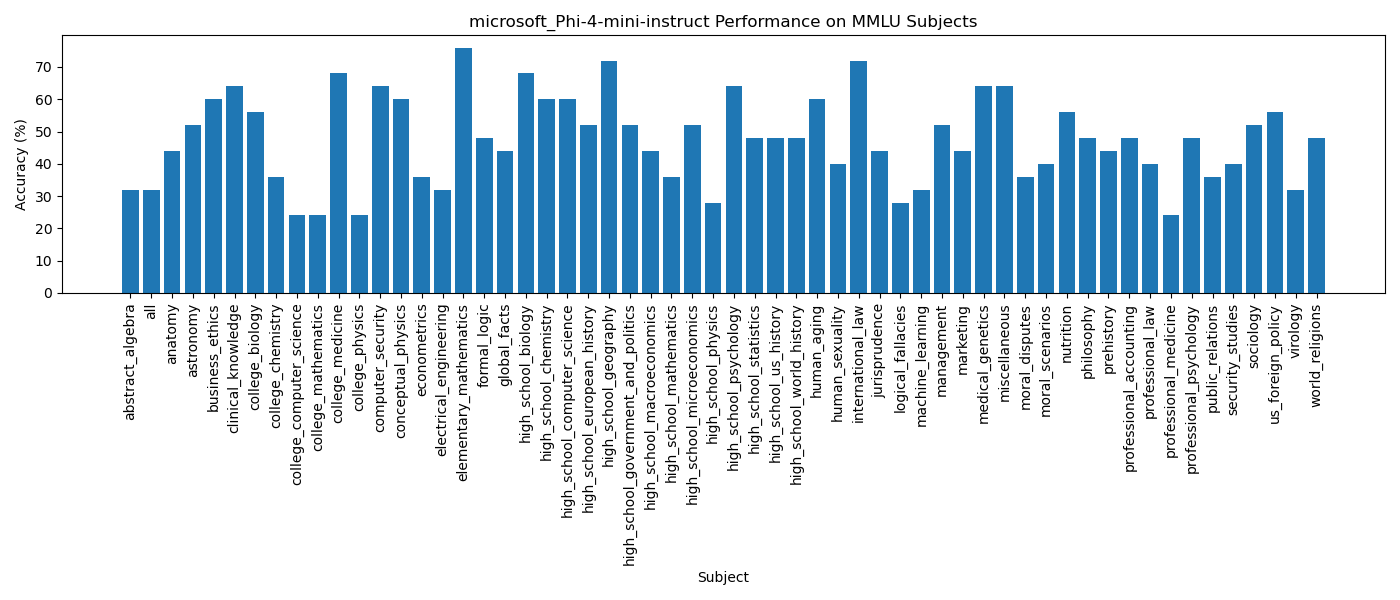
Accuracy "all" = 31%
Challenges_in_building_LLMs
By Arun Prakash



