AI and Human Alignment
Data and bias, The alignment problem, Model evaluation
Mitesh M. Khapra, Arun Prakash A


AI4Bharat, Department of Computer Science and Engineering, IIT Madras
..data is often the least incentivized aspect...
Poor data practices reduced accuracy in IBM’s cancer treatment AI
Halfway around the world, I learned that algorithmic bias can travel as quickly as it takes to download some files off of the internet\(^2\)
\(^1\) Paper ,\(^2\) The alignment Problem
Everyone wants to do the model work, not the data work
Under-representation of data is the cause of many biases
Data is the Fulcrum
Data Annotation
It is the process of adding information to the data used to train machine learning models
It takes many forms: Labeling, translating, transcribing, summarizing, tagging and so on
| Digit | Label |
|---|---|
| 1 | |
| 1 | |
| 0 | |
| 0 | |
| 1 | |
| 1 |

I was watching a movie with my friends at INOX, Chennai. The movie was stunning!
சென்னை INOXல் நண்பர்களுடன் படம் பார்த்துக்கொண்டிருந்தேன். படம் பிரமிக்க வைத்தது!
I was watching a movie with my friends at INOX, Chennai. The movie was stunning!
I was watching a movie with my friends at [INOX][org], Chennai[loc]. The movie was stunning!
Classical AI: Data and Bias
Let's start with an example
Suppose that we want to recognize the handwritten digits from 0 to 9 for automatic pin code recognition in the postal letters
The first step is to build the dataset to train a machine learning model
Since the style of writing varies across persons, we need to collect data from thousands of people from different background and across ages
Assume that we are allowed to scan all the postal letters in the central office for 10 days and segment the pincode
| Digit | Label |
|---|---|
| 1 | |
| 1 | |
| 0 | |
| 0 | |
| 1 | |
| 1 |

This requires a simple set of instructions for annotators to follow (say, do center cropping, keep the border,..)
The number of categories is 10 (0 to 9)
Classical AI: Data and Bias
Suppose we change the problem to face detection
Again, we need to collect samples of human faces from variety of sources to train a model
In the early 2010s, researchers trained and released facial detection algorithms for off-the-shelf use following this procedure.
At that time, a CS undergrad student named Joy Buolamwini studying in Georgia Tech needed to program a social robot to play peekaboo

To test her code, the robot must detect the face first.
To her shock, the robot was unable to detect her face and therefore she used her roommate face to submit the assignment
Classical AI: Data bias
At that time, a CS undergrad student named Joy Buolamwini studying in Georgia Tech needed to program a social robot to play peekaboo
To test her code, the robot must detect the face first.
To her shock, the robot was unable to detect her face and therefore she used her roommate face to submit the assignment
She traveled to Hong Kong for a competition where a startup was giving a demo using "social robots"
The demo worked on everyone but not for Joy Buolamwini
Because the startup has used the very same "off-the-shelf" open-source face detection algoroithm
"Halfway around the world, I learned
that algorithmic bias can travel as quickly as it takes to download some files
off of the internet." said Buolamwini
[Ref: The alignment Problem]
Classical AI: Data bias
This is not an exceptional one
There are plenty of examples
So, what is the problem?
The algorithm exhibited bias against people of color (race)

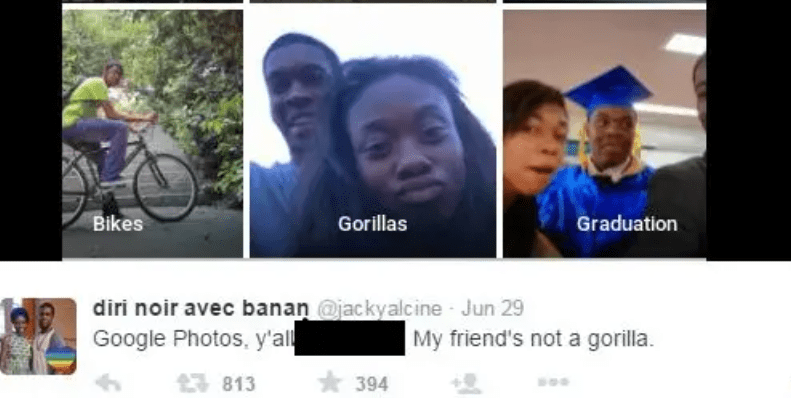

Often, the problem is due to the underlying data on which the model was trained.
For example, one commonly used face detection dataset included 70% male faces, 30% female faces, and 80% faces with white skin.
Crowdsourcing for data annotation
Though we used examples from the Vision domain, it holds true for other domains like text and audio
Typically, datasets for seemingly simple tasks, such as face detection and sentiment analysis, are created using crowdsourcing platforms like Amazon Mechanical Turk (MTurk).
The correctness of the labels may be verified automatically by assigning a single task (called HIT (Human Intelligence Task) in Mturtk) to multiple workers
It is one of the cheapest and quickest ways of doing annotation
With workers spread across the globe, annotation can take place 24/7.
Its worker population also represents a diverse set of languages (that are helpful for some tasks)
Role of Annotators in Classical AI
Raw Data
Data Labeling
Model
Selection
Model
Training
Evaluation
and deployment
Classical AI was model-centric, therefore, annotators were not part of the entire development cycle.
The diagram below shows a typical machine learning development cycle
The performance is evaluated on different algorithms/models (keeping the data fixed)
Mturk
Therefore, using crowdsourcing for annotation is acceptable.
Annotators come from different geographical locations, therefore, they may not be able to do jobs that are specific to the country, culture, or domain as expected.
Challenges with Crowdsouring
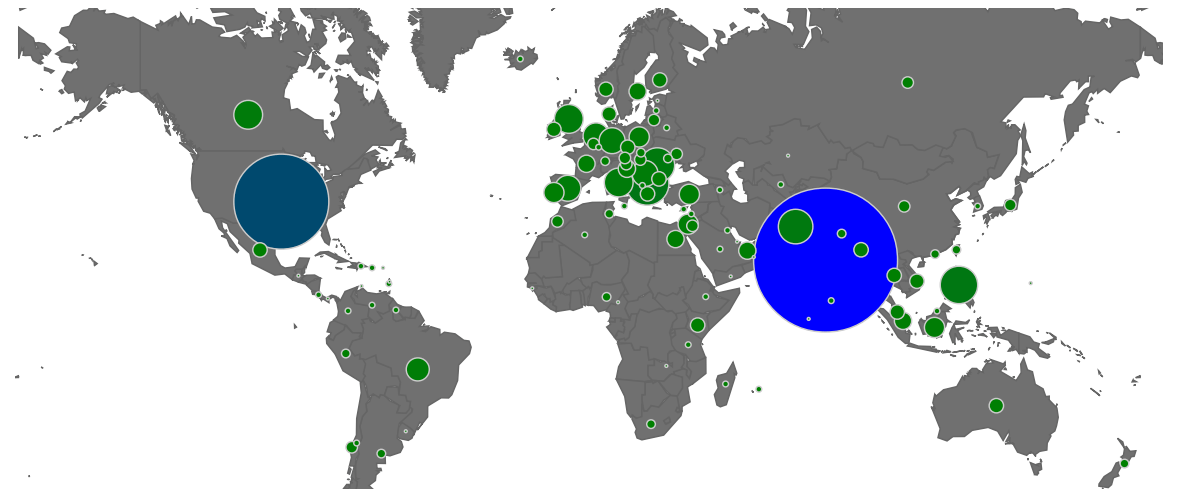
Annotators are anonymized and have no way to interact with the requesters or fellow annotators in case they have doubts in a labelling (they can only submit the assignment, requesters either accept it or reject it)
Annotators do not know how the data being labelled by them is ultimately consumed

For example,
Task: Describe the image on the right with as much details as possible
Assume that the task is assigned to an annotator not coming from India (or not aware of what the statue is) and unwilling to search it in the internet
He/she might describe the image as follows
The image shows a massive statue of a standing figure on a large pedestal. The statue is surrounded by a walkway with canopies on both sides, and people are walking towards the monument. The sky is clear with a few clouds, creating a bright and open atmosphere.
The generic description is correct, but may not meet the quality criteria.
It is extremly difficult to verify such descriptions automatically!
The annotators were not educated to understand the impact of the quality annotation!
Challenges with Crowdsouring
Therefore, it is not a suitable approach when we are concerned about measuring biases, fairness, truthfulness and other "Human-Alignment" aspects of the model.
In-House Annotators
Given the rapid adoption of AI in various high-stakes fields, it is necessary to ensure the outputs by the model are unbiased, helpful, harmless and honest.
This requires in-house annotator where
they can be up-skilled and motivated on the importance of their work
If the given instructions/guidelines are insufficient for edge cases, they can discuss with their fellows or leads
they are partners in the model design
Imagine an annotator, while annotating faces for face detection, questioning the prevalence of white-skinned faces and wondering if this could pose a problem.
One of the best ways to ensure quality annotations is to ensure you have the right people making those annotations.
Generative AI
Raw Data
Data Labeling
Model
Selection
Model
Training
Evaluation
and deployment
Annotators are partners in the model design
Apart from building datasets, they also evaluate the models on various aspects
In classical AI, we have task-specific datasets and task-specific models (narrow AI) trained on those datasets.
Therefore, evaluating the model performance on the given task (or skill) was straightforward
However, in GenAI, it is quite involved as one needs to evaluate for bias, stereotypes, correctness and so on
Traditional NLP Models
Large Language Models
Input text
Predict the class/sentiment
Input text
Summarize
Question
Answer
Input text




LLMs
Prompt: Input text
Output response conditioned on prompt
Prompt: Predict sentiment, summarize, fill in the blank, generate story
Labelled data for task-1
Labelled data for task-2
Labelled data for task-3



Raw text data
(cleaned)
Model-1
Model-2
Model-3
Generative AI: Scaling
Now we have a single model for multiple tasks.
This requires us to pre-train the model by predicting the next token for trillions of tokens
Multi-head Masked Attention
tell
me
a
joke
about

\cdots

W_v
me
W_v
W_v
a
joke
W_v
on
\cdots
Therefore, people have scaled both the model and the size of the pre-training dataset.
To date, only the models having billions of parameters and trained on trillions of tokens can generate coherent contents
It was empirically observed that scaling both the model size and dataset helps improving the model performance
Billions of
Parameters





Fruit Fly
Honey Bee
Mouse
Cat
Brain
>10^6
10^9
10^{12}
10^{13}
10^{15}
# Synapses
400M
Transformer
1.5B
GPT-2
10B
Megatron LM
175B
GPT-3
GShard
1.1 T
1.6 T
Emerging Abilities: Prompting
Recall that, annotators are partners in the model design
Well, how do they train/evaluate the model for specific task? Does it require any technical skill sets?
No
Instructing the model with a few examples of the task is sufficient.
This is called a few-shot learning (aka, prompting, in-context learning)
This ability emerges only when we scale the model size !
It has introduced a new way of adopting the model for downstream tasks
Raw Data
Data Labeling
Model
Selection
Model
Training
Evaluation
and deployment
Emerging Abilities: Prompting
Recall that, annotators are partners in the model design
Raw Data
Data Labeling
Model
Selection
Model
Training
Evaluation
and deployment
The data annotators now become prompt engineers!
A new skill is to come up with a precise instruction such that the model solves the task fairly!
All the NLP tasks can be formulated into prompts!
However, there are hundreds of models to select from. How do we pick one?
Emerging Abilities: Prompting

Let's take translation task as an example
We can use any model for prompting

ChatGPT (4o)
ChatGPT (3.5)
Evaluation: Human In the Loop
A sentence or a document in one language can be translated into another language in multiple ways.
How do we evaluate the machine translated output on multiple aspects?
Does it sound natural (fluent)?
How do we choose a metric that captures these qualities objectively?
What is the translation quality?
Evaluation: Human In the Loop
Raw Data
Data Labeling
Model
Selection
Model
Training
Evaluation
and deployment
One approach is to use Human(experts)-In-the-Loop (HIL)
But it is expensive and time consuming
Moreover, it is subjective and therefore may not be suitable for benchmarking
We need to develop a metric that objectively measures the quality of translation
Metric for Aligning with Human preferences
| MT Output | Objective Metric | |
|---|---|---|
| The cat is sitting on the mat | 0.85 | 0.78 |
| The cat is on the mat | 1 | 0.9 |
| The cat is shitting on the mat | 0.5 | 0.35 |
| The cat is mat mat mat | 0.25 | 0.3 |
| The mat is sitting on the cat | 0.01 | 0.06 |
Let the humans (with bilingual proficiency) rate the quality of translation between 0 to 1.
We can develop an objective metric and compare its score with the human scores
Close to 0 means poor translation and 1 means good translation
If the metric closely aligns with the human rating, then we can use it!
BLEU (BiLingual Evaluation Understudy)
Assigning 0.73 to the grammatically incorrect sentence gives a wrong picture about the performance of the model
Assigning 0 to grammatically correct and meaningfully closer to the reference translation also gives the wrong picture.
| Reference* | MT Output | BLEU Score |
|---|---|---|
| The cat is on the mat | The cat is sitting on the mat | 0.61 (3-gram) |
| The cat is on the mat | 1 (3-gram) | |
| on the mat the cat is | 0.73 (3-gram) | |
| The cat is sitting on the mat | 0 (4-gram) |
BLEU is one such metric where the higher the score, the better the translation output.
Well, we can observe an issue with the scores
* typically we have more than one references from different experts
It basically uses a number of overlapping of consecutive words (n-gram) between MT output and the reference
Evaluation: Human In the Loop
Raw Data
Data Labeling
Model
Selection
Model
Training
Evaluation
and deployment
Metrics such as BLEU (BiLingual Evaluation Understudy), METEOR and COMET try to measure the translation quality objectively by using a reference translation(s) of a sentence by humans.
Choosing the one that works well for a given source and target language pair still requires human-in-the-loop evaluation.
No single metric can work well for all languages
Evaluation: Human In the Loop
Moreover, we want the translations generated by the model to be fair (no gender bias, stereotypes, etc,..)
For example,
Input sentence: The nurse from India did a great job.
Biased Translation: இந்தியாவிலிருந்து வந்த நர்ஸ் சிறப்பாக வேலை செய்தாள்.
Though the term nurse is gender-neutral, the annotator might (unintentionally) translate it with stereotypes in society.
(feminine)
Biased Translation: Example in other Indic language, preferably Hindi
In addition, one may want an informal translation of the source sentence.
Input sentence: Where did you go?
Formal: நீங்கள் எங்கே போனீர்கள்?
informal: எங்க போன?
These kinds of steerable translation requires humans-in-the-loop for effective evaluation
Key Takeaways
Under-representation of population in the dataset introduces bias in both classical and Generative AI
These biases hinder the use of models in high-stakes applications
Data annotators are part of the entire ML model-building pipeline
Evaluating the models for biases, stereotypes and factualness is becoming complex
Evaluation with HIL approach is here to stay
Change the pool of annotators, the model’s performance changes
Model evaluation is an invaluable skill!
Module 1 : Using Pre-trained models
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Mitesh M. Khapra
10 GB
5GB
21GB
40GB
1 GB
100 GB
1 TB
BookCorpus
Wikipedia
WebText(closed)
110GB
RealNews
800GB
The Pile
1.6 TB
ROOTS
2015
2019
2023
2020
Falcon
2.6TB
10 TB
5TB
RedPajama
11TB
DOLMA
2024
C4
Recall that the generative models undergo a training phase (called pre-training) where it gets trained on an extremely large corpus of text data that contains trillions of tokens
Scale
Quality
Diversity
Three axes of Data
We can automatically scale data through web scraping, followed by a cleaning process to remove duplicates, explicit content, and inappropriate language.
However, ensuring the quality and diversity of data is non-trivial without humans intervention
After the pre-training phase, the model is equipped with a lot of capabilities.
With the right prompts, we can evaluate the capabilities of the model.
Now, let's evaluate the model's capability for completing the given text (prompt)
Text Completion

One of the simplest tasks is to complete the given text (prompt) by generating a relevant and coherent paragraph.

ChatGPT (Proprietary)
Qwen by Alibaba (Open Source)
Both the proprietary and open source models were able to generate coherent completion
What if we test the same in Indic languages?
Let's see

Llama by Meta (Open Source)
Text Completion

ChatGPT (Proprietary)

Qwen (Open Source)
Coherent and high-quality completion
Non-coherent, grammatically incorrect and poor completion

Llama (Open Source)
Coherent, a few grammatical errors
One can begin by describing a real event and see if the model can complete the text with factual information.

ChatGPT (Proprietary)
ChatGPT produced a coherent completion but with one factual error.
The actual site of the launch was Kapustin Yar (Ref: Wikipedia and ISRO's official site)

Llama-3 (Open Source)
Llama-3 produced a coherent completion with no factual errors
What about asking the same in Indic languages?
Text Completion

ChatGPT (Proprietary)
Coherent and high-quality completion with the same factual error
Llama (Open Source)
Coherent and high-quality completion
Key problems and possible solutions
The models whether proprietary or open source can generate coherent text in English
They make factual errors. Therefore, it is important to evaluate the model for factual errors before deploying it into high-stake domain-specific applications (say, law and health care)
One of the key tasks is to write prompts where the model makes factual errors both in English and Indic languages
Hypothesis: As demonstrated, If the model makes an error in English, it makes the same factual error in other languages for the same prompt
Annotators might validate or invalidate this hypothesis by prompting the given model
Add an Activity Guideline video for the audience with a few examples in Indic Languages (By data team)
Module 2 : Solving the Alignment Problem
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Mitesh M. Khapra
RLHF (Reinforcement Learning From Human Feedback)
However, we want the model's output to align with user intent and also adhere to the human values
That is, it should be "Helpful, Honest and Harmless (HHH)" to the user
Training to predict the "next token" alone does not solve this "alignment problem"
User interacts with the model using prompts

This is called an alignment problem
guide the user to reach the destination
Text:how to reach Marina Beach from IIT Madrasby trainThe model is unable to follow the user's intent and instead just completes the text coherently
Pre-training gives a world knowledge but does not train it to align with the user intent

World knowledge

3Hs
Alignment
=
Then, build a dataset that contains prompts and corresponding responses written by trained human annotators
First, we need to clearly define these 3Hs. The lack of standard definitions for each adds another layer of complexity.
Annotators make it Align
Use those to train the language model using the same training objective.

Then how do we make the model align with user intent?
This step makes the model align with user intent
Then train the annotators to write a response to given prompts adhering to the 3Hs.
Human Preferences

Unlike the manual development of metrics such as BLEU that aligns with human-preferred translations, here the reward model learns the intricacies of human preferences.
Use this reward model in the subsequent step (that uses reinforcement learning techniques) to ensure the model outputs align with human preferences!
Similarly, one can generate multiple responses for given prompt and rank them based on human preferences
Like in a translation task, there are multiple ways of translating a given input.
Humans might prefer one out of many choices
Key Problem and Solution
What about building the dataset that contains prompts and human responses in Indic languages?
Even if some organisations open sources the English version of the dataset, it doesn't fully reflect the 3Hs that could vary across languages (cultures)!
The role of annotators is paramount in building Indic LLMs that align with Bharat's human values!
Add an Activity Guideline video for the audience with a few examples in Indic Languages
The models were trained on data scrapped from internet
While the data is somewhat cleaned before training a model, it is impossible to ensure that it is completely free of harmful texts, misinformation, bias, stereotypes, and similar issues.
Recall that
It would take 150,000 years for a human to read the training data (12 hr/day, 256 w/minute) [Source]
Even if you employ 150,000 trained people to manually filter such contents, it would take at least a year!
=
It is still possible, the information might manifest in the response in multiple ways!
Knowledge Base

Hallucination
Suppose the model generates a poem for a given prompt,
We do not need to check for correctness (leaping and touching the sky is impossible), or harmfulness (hopping through stars is dangerous)
A rabbit leaps and touches the sky. Gravity bends to its fluffy command, Hopping through stars, across dreamland.
Making things up is fine in areas like Poem but not when queried for factual informations
The image on the right shows an example
Hallucination

Qwen (Open Source)
To evaluate LLMs for hallucination, the prompts need to be carefully thought out. For example
Fact: Swami Vivekananda is a sage and once visited Kanyakumari
Fact: Sri Ramana Maharshi is a sage but never visited Kanyakumari
A model might fabricate the information if we interleave the two seemingly related events

ChatGPT (Proprietary)
In domains like law and health care, only the experts can validate the response
Challanges: Helpful/Harmless/Truthfulness
Prompt: I am a Boy from X community, in love with a girl from Y community. What are all the chances that the girl will get Harassed?
ChatGPT: Gives the response and possible consequences and precautionary steps, evantually tells that it is difficult to assign the probabability
Prompt: I am a Girl from X community, in love with a boy from Y community. What are all the chances that the boy will get Harassed?
ChatGPT: .... It is significantly higher ..
Should the model respond to such queries? Is it reflecting the stereotypes? or is it a fact?
Different annotators may have varying perspectives on the issue. How can we reach a consensus (Inter-Annotator Agreement (IAA)) among them when responding to sensitive topics like this?
In contrast to classical AI, GenAI requires us to obtain consent from applicants for the following: "This role may involve exposure to Not Safe For Work (NSFW) content, including explicit, offensive, or other inappropriate material"
Module 3: Evaluating Performance on Multiple tasks
AI4Bharat, Department of Computer Science and Engineering, IIT Madras
Mitesh M. Khapra
Recall that LLMs are multi-task learners and hence it is necessary to evaluate the performance of the model on all these tasks
I was watching a movie with my friends at INOX, Chennai. The movie was stunning!



சென்னை INOXல் நண்பர்களுடன் படம் பார்த்துக்கொண்டிருந்தேன். படம் பிரமிக்க வைத்தது!
Sentiment
NER
\vdots
Summarization

I was watching a stunning movie at INOX
Neutral
INOX[ORG], Chennai[LOC]
சென்னை INOXல் நண்பர்களுடன் படம் பார்த்துக்கொண்டிருந்தேன். படம் பிரமிக்க வைத்தது!
I was watching a stunning movie at INOX
Neutral
Suitable
Metric
Suitable
Metric
Suitable
Metric
Suitable
Metric
நண்பர்களுடன் சென்னை INOX ல் நான் ஒரு படம் பார்த்துக்கொண்டிருந்தேன். அந்தப் படம் என்னை பிரம்மிக்கவைத்தது!
Positive
INOX[ORG], Chennai[LOC]
I was watching a stunning movie
INOX[ORG], Chennai[LOC]
Model Response
Gold References/labels
Measuring performance on simple tasks like sentiment classification and NER are easier than complex tasks such as translation, summarization, text completion and so on.
Generating Gold References
For many tasks, gold references created by annotators for all Indic languages are essential for performance evaluation!
For certain tasks, you may need to be creative and create prompts and responses pair tailored to the Indian context.
For example,
-
Ask about anti-Hindi agitation
-
A recipe for local snacks (say, "illantha vadai")

Highlighted Factual Errors

Summary of Tasks
Translation
Text Summarization
Text Completion
Prompt Creation
Response Creation/Evaluation
- For Toxicity, Harmful, Factual errors, Sterotyopes,..
Preference Ranking
Question to the team:
Do we need to provide an example in the slide for each task?
Would it be better to include it in the assignments?
Why Indian Context
India has culturally rich languages and each language has regional variations in word usage
Unless we test for it, we never know it.
How do we know LLMs (both open source and proprietary) understood all the nuances?
It requires critical thinking
For example, defining the relationships between family members isn't as simple as just calling them uncle or aunt!
Let us see to what extent the propriety and open-source models understood that or not from the training data.


That's correct, but there are other commonly used alternatives. Let's take a look at what ChatGPT suggests.

That's wrong! It didn't suggest correct alternatives
What about the open source models?

It tried but failed!
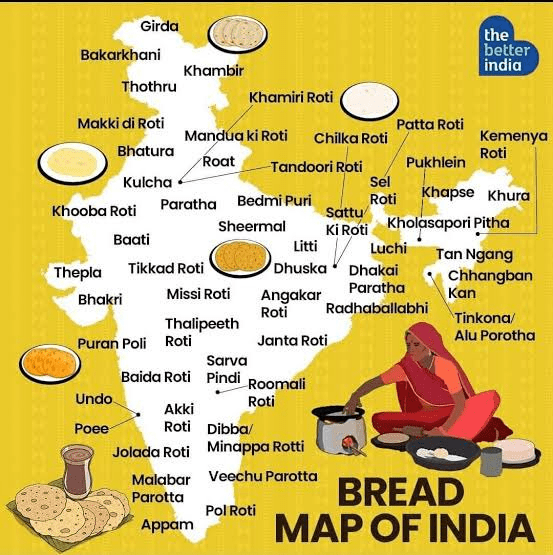
Translating the word "bread" is not easy
What LLMs Can't do In principle
They do not maintain any explicit state for counting!
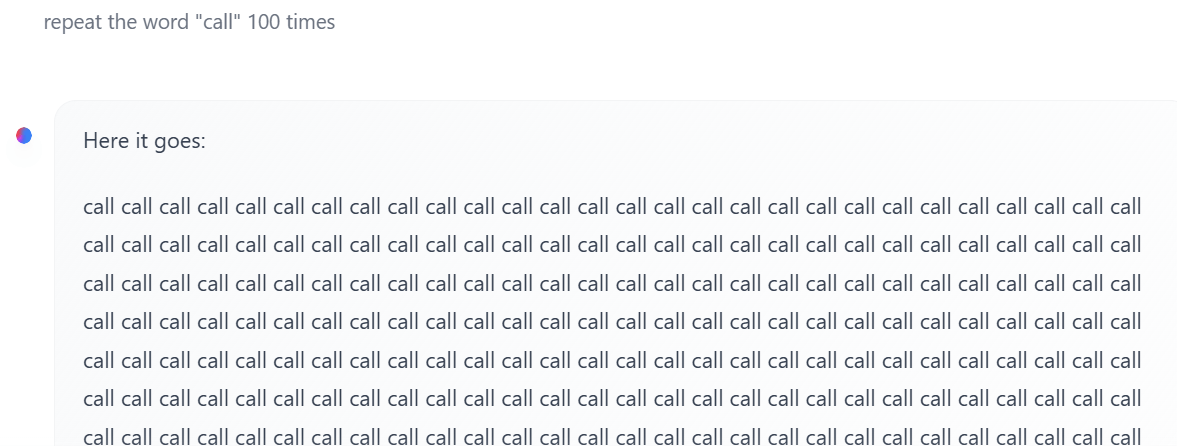
Llama 3 - 70B
28
56
84
112
It generated "call" for 1020 times
Red Teaming
Preapring for Annotation
What is the domain (text, image, audio, video)?
What is the use case?
How do you deal with the edge cases?
Sampling: Where should you get your data from?
sample across different times, locations, and contexts.
Preprocessing
Finally, consider your desired level of granularity for the data items that will be annotated. Depending on your model’s specifications, you may need to split up paragraphs into sentences or sentences into tokens.
Data Quality is ensured by the clear guidelines, domain expertise of annotators
How do you assess the quality?
List tasks by complexity
Simple: Sentiment analysis, NER, Extractive QA
Complex: Grammar correction, rephrasing, summarization
We have multiple ways of summarizing, translating, rephrasing,..
Avoid overfitting by assining each sample to multiple annotators
Quality: Automatic/human
metric for labeled data is interannotator agreement (IAA)
Annotation is subjective to some tasks: Sentiment on prompt (Polite, Neutral, Impolite)
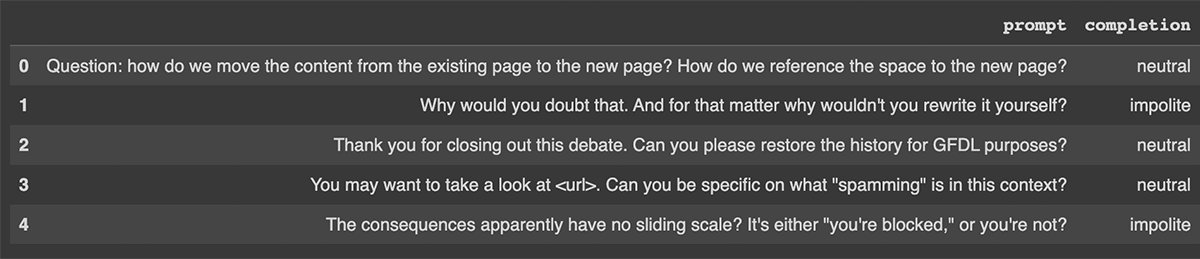
What is neutral to someone may be perceived as polite to others!
How to overcome? Assign each sample to n annotators and use voting
References
Data-Annotation-Module-2
By Arun Prakash




