Introduction to Large Language Models
Lecture 6: The Bigger Picture and the road ahead
Mitesh M. Khapra, Arun Prakash A


AI4Bharat, Department of Computer Science and Engineering, IIT Madras
In the previous lecture, we dived deep into T5 and the choices behind it

Many Large Language Models have been released since then, and the number is growing
In this lecture, we attempt to group some of these prominent models and see how they differ in terms of using pre-training datasets and modifying various components of the architecture
One way is to group the models based on the type of architecture (Encoder, Encoder-Decoder,Decoder) used.
Image source: Mooler
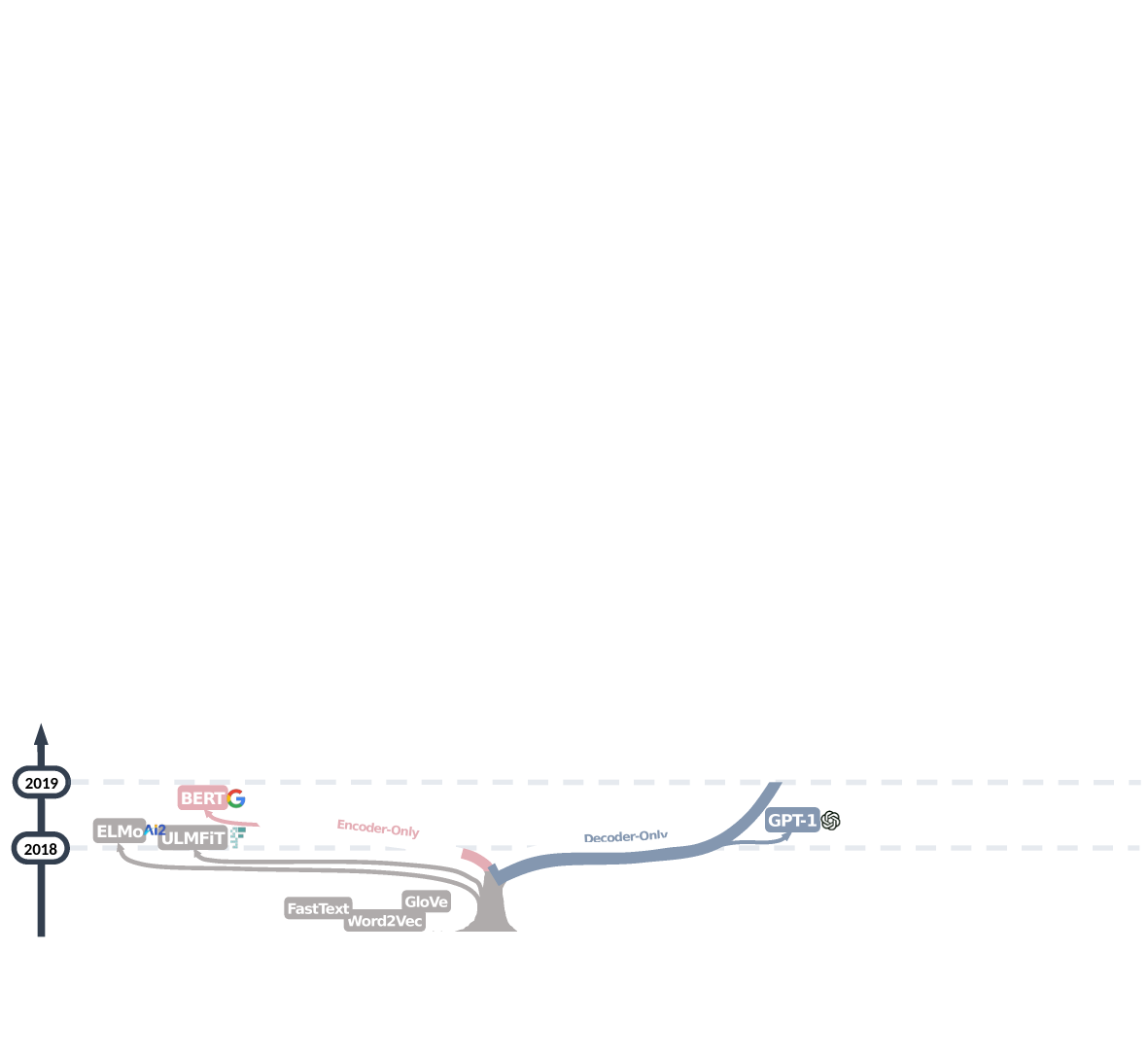
Encoder-only models (BERT and its variants) dominated the field for a short time soon after the introduction of BERT
Decoder-only models (GPT) soon emerged for the task of Language modeling

Encoder only models , BERT and its variants dominated the field for a short time since the introduction of BERT
GPT-2 and T5 advocated for decoder only models and encoder-decoder models, respectively.
Model
Dataset
-
Scale the model or dataset or both?
-
What is the proportion of scaling?
Encoder only models , BERT and its variants dominated the field for a short time since the introduction of BERT
It did not last long, GPT-2 and T5 advocated for the decoder only model and encoder-decoder model, respectively.
"Scaling laws" lead to a race to build larger and larger models!
Scaling laws
Model
Dataset

GPT-3 with 175 Billion parameters
"Scaling laws" lead to a race to build larger and larger models!

GPT-3 with 175 Billion parameters (proprietary)
Scaling law stirred the researchers to build really large models!
GPT-J with 6 Billion parameters (open sourced)
Jurassic-1 with 178 Billion parameters (proprietary)
Gopher with 280 Billion parameters (proprietary)
GLaM with 1200 Billion parameters (proprietary)

Instruct GPT proposed RLHF based alignment objective for conversational models
Decoder-only models dominated the field
Meta release OPT with 175 Billion parameters (open sourced)
ChatGPT built on top of the ideas in InstructGPT

The number of (open and closed ) LLMs is still growing
LLaMA-3 is planned for 2024!
Instruct GPT proposed RLHF based alignment objective for conversational models
Decoder-only models dominated the field
Meta release OPT with 175 Billion parameters (open sourced)
ChatGPT built on top of the ideas in InstructGPT
Even if we select only the decoder branch in the evaluation tree
there would still be dozens of models
So, what do they differ in despite following the same architecture?
Even if we select the branch of decoder only models in the evaluation tree
Position Encoding
- Absolute
- Relative
- RoPE,NoPE
- AliBi
Attention
- Full/sparse
- Multi/grouped query
- Flash
- Paged
Normalization
- Layer norm
- RMS norm
- DeepNorm
Activation
- ReLU
- GeLU
- Swish
- SwiGLU
- GeGLU
- FFN
- MoE
- PostNorm
- Pre-Norm
- Sandwich
Multi-Head Masked Attention
Feed forward NN
Add&Norm
Add&Norm
- Objective
- Optimizer
there would still be dozens of models
So, what do they differ in despite following the same architecture?
-
The dataset used to train the model (common crawl being the source for majority of the datasets)
BookCorpus
OpenWebText
C4
CC-Stories
WikiPedia
Pushift.io
BigQuery
The Pile
ROOTS
REALNEWS
CC-NEWS
StarCoder
RedPajama
-
Various design choices to reduce computational budget, increase the performance...
+
- Training steps
DOLMA
Position Encoding
BookCorpus
OpenWebText
C4
CC-Stories
WikiPedia
Pushift.io
BigQuery
The Pile
ROOTS
REALNEWS
CC-NEWS
StarCoder
RedPajama
+
Unifying Diagram
Attention
MLP
Add&Norm
Absolute
Relative
RoPE
NoPE
AliBi
MHA
MQA
GQA
Flash
Paged
Sparse
RMS
Layer
Deep
FFNN
MoE
Add&Norm
RMS
Layer
Deep
ReLU
GeLU
Swish
SwiGLU
GiGLU
Objective:
Optimizer:
CLM
MLM
Denoising
AdamW
Adafactor
LION
N : X
WebText
Position Encoding
BookCorpus
OpenWebText
C4
CC-Stories
WikiPedia
Pushift.io
BigQuery
The Pile
ROOTS
REALNEWS
CC-NEWS
StarCoder
RedPajama
+
GPT-1
Attention
MLP
Add&Norm
Absolute
Relative
RoPE
NoPE
AliBi
MHA
MQA
GQA
Flash
Paged
Sparse
RMS
Layer
Deep
FFNN
MoE
Add&Norm
RMS
Layer
Deep
ReLU
GeLU
Swish
SwiGLU
GiGLU
Objective:
Optimizer:
CLM
MLM
Denoising
AdamW
Adafactor
LION
N : 12
WebText
Position Encoding
BookCorpus
OpenWebText
CC
CC-Stories
WikiPedia
Pushift.io
BigQuery
The Pile
ROOTS
REALNEWS
CC-NEWS
StarCoder
RedPajama
+
GPT-3 175B
Absolute
Relative
RoPE
NoPE
AliBi
Objective:
Optimizer:
CLM
MLM
Denoising
AdamW
Adafactor
LION
N : 96
Norm & add
RMS
Layer
Deep
MLP
FFNN
MoE
ReLU
GeLU
Swish
SwiGLU
GiGLU
Attention
MHA
MQA
GQA
Flash
Paged
Sparse
Norm&add
RMS
Layer
Deep
WebText
Position Encoding
BookCorpus
OpenWebText
mC4
CC-Stories
WikiPedia
Pushift.io
BigQuery
The Pile
ROOTS
REALNEWS*
CC-NEWS*
StarCoder*
RedPajama
+
PaLM 540B
Absolute
Relative
RoPE
NoPE
AliBi
Objective:
Optimizer:
CLM
MLM
Denoising
AdamW
Adafactor
LION
N : 118
Add&Norm
RMS
Layer
Deep
MLP
FFNN
MoE
ReLU
GeLU
Swish
SwiGLU
GiGLU
Attention
MHA
MQA
GQA
Flash
Paged
Sparse
Add&Norm
RMS
Layer
Deep
WebText
BookCorpus
OpenWebText
C4
CC-Stories
WikiPedia
Pushift.io
BigQuery
The Pile
ROOTS
REALNEWS*
CC-NEWS*
StarCoder*
RedPajama


mC4
Filtering Rules
Road ahead
Data Sources, Data Pipelines, Datasets

DOLMA
Position Encoding
BookCorpus
OpenWebText
C4
CC-Stories
WikiPedia
Pushift.io
BigQuery
The Pile
ROOTS
REALNEWS
CC-NEWS
StarCoder
RedPajama
+
Attention
MLP
Add&Norm
Absolute
Relative
RoPE
NoPE
AliBi
MHA
MQA
GQA
Flash
Paged
Sparse
RMS
Layer
Deep
FFNN
MoE
Add&Norm
RMS
Layer
Deep
ReLU
GeLU
Swish
SwiGLU
GiGLU
Objective:
Optimizer:
CLM
MLM
Denoising
AdamW
Adafactor
LION
N : X
DOLMA
Road ahead
Position Encoding
BookCorpus
OpenWebText
C4
CC-Stories
WikiPedia
Pushift.io
BigQuery
The Pile
ROOTS
REALNEWS
CC-NEWS
StarCoder
RedPajama
+
Attention
MLP
Add&Norm
Absolute
Relative
RoPE
NoPE
AliBi
MHA
MQA
GQA
Flash
Paged
Sparse
RMS
Layer
Deep
FFNN
MoE
Add&Norm
RMS
Layer
Deep
ReLU
GeLU
Swish
SwiGLU
GiGLU
Objective:
Optimizer:
CLM
MLM
Denoising
AdamW
Adafactor
LION
N : X
Road ahead
Position Encoding
BookCorpus
OpenWebText
C4
CC-Stories
WikiPedia
Pushift.io
BigQuery
The Pile
ROOTS
REALNEWS
CC-NEWS
StarCoder
RedPajama
+
Attention
MLP
Add&Norm
Absolute
Relative
RoPE
NoPE
AliBi
MHA
MQA
GQA
Flash
Paged
Sparse
RMS
Layer
Deep
FFNN
MoE
Add&Norm
RMS
Layer
Deep
ReLU
GeLU
Swish
SwiGLU
GiGLU
Objective:
Optimizer:
CLM
MLM
Denoising
AdamW
Adafactor
LION
N : X
Road ahead
q_0k_0^T
q_0k_0^T
i=0
i=1
q_1k_0^T
q_1k_1^T
q_0k_0^T
i=2
q_1k_0^T
q_1k_1^T
q_2k_0^T
q_2k_1^T
q_2k_2^T
v_0
v_0
v_1
v_1
v_2
v_0
Position Encoding
- Absolute
- Relative
- RoPE,NoPE
- AliBi
Attention
- Full/sparse
- Multi/grouped query
- Flash
- Paged
Normalization
- Layer norm
- RMS norm
- DeepNorm
Activation
- ReLU
- GeLU
- Swish
- SwiGLU
- GeGLU
- FFN
- MoE
- PostNorm
- Pre-Norm
- Sandwich
Multi-Head Masked Attention
Feed forward NN
Add&Norm
Add&Norm
- Objective
- Optimizer
BookCorpus
OpenWebText
C4
CC-Stories
WikiPedia
Pushift.io
BigQuery
The Pile
ROOTS
REALNEWS
CC-NEWS
StarCoder
RedPajama
+
- Training steps
DOLMA
Lecture-6-BigPicture
By Arun Prakash




