Large Language Models:
Challenges and Opportunities


Mitesh M. Khapra, Arun Prakash A

Evolution of How Information is Stored and Retrieved !
Stone/Iron Age
Industrial Age
Digital Age
Carved in Stones
Written on papers
Digitized
Parameterized





The Age of AI [has begun]*
Store and Retrieve
Store and Retrieve
Store and Retrieve
Store and Generate!











Magic Box


Creative Text Generation
"Any sufficiently Advanced Technology is Indistinguishable from Magic"

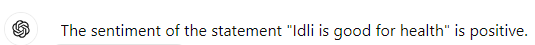
Simple Sentiment Classification
Magic Box
"Any sufficiently Advanced Technology is Indistinguishable from Magic"

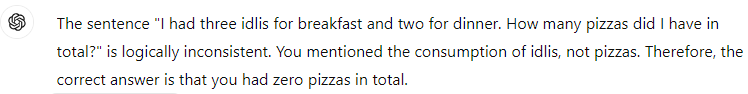
Logical Reasoning
Magic Box
"Any sufficiently Advanced Technology is Indistinguishable from Magic"
Doing arithmetic


Magic Box
"Any sufficiently Advanced Technology is Indistinguishable from Magic"
Who is inside the Magic box?

I'm sure there must be a few expert dwarves in the box!
That's why we get convincing responses for all questions
Who is inside the Magic box?
Well, It generates an Image from a textual description!

Image: Children suspects some people are inside a radio or television set back in 1970's, India.
There must be a dwarf inside the box..
Who is inside the Magic box?
Image: Children suspects some people are inside a radio or television set back in 1970's, India.
Well, It generates an Image from a textual description!

There must be a dwarf inside the box..

Magic Box

"Any sufficiently Advanced Technology is indistinguishable from Magic"
Magic Box
Multi-head Masked Attention
N \times
tell
me
a
joke
about
idli

\leftarrow prompt \rightarrow
\leftarrow response \rightarrow
\leftarrow prompt \rightarrow
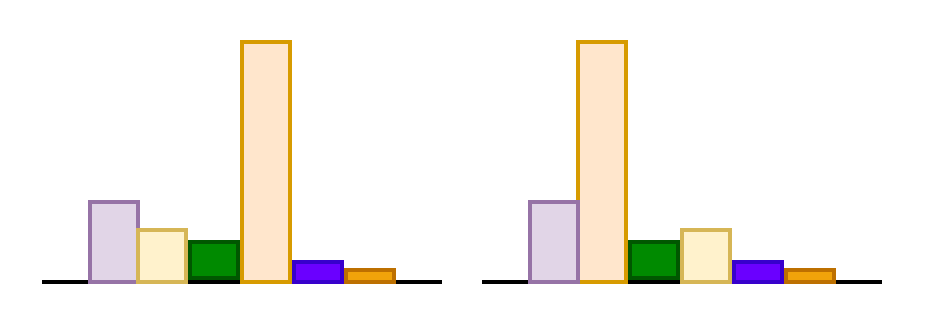

W_v
why
why
W_v
W_v
did
the
did
\leftarrow response \rightarrow
\cdots
\cdots
Multi-head Masked Attention
tell
me
a
joke
about
idli
W_v
why
why
W_v
W_v
did
the
did
\cdots
\cdots
The Magic:
Train the models to predict next word given all previous words
W_v
idli
the
“The magician takes the ordinary something and makes it do something extraordinary.”

Traditional NLP Models
Large Language Models
Input text
Predict the class/sentiment
Input text
Summarize
Question
Answer
Input text
LLMs
Prompt: Input text
Output response conditioned on prompt
Prompt: Predict sentiment, summarize, fill in the blank, generate story
Labelled data for task-1
Labelled data for task-2
Labelled data for task-3



Raw text data
(cleaned)
Model-1
Model-2
Model-3





Trillions of
Tokens
Billions of
Parameters
Zetta FLOPS
of Compute
LLMs
+
+
Three Stages
Pre-training
Fine tuning
Inference
Trident of LLMs
Trillions of Tokens
LLMs
W_v
Next token
“The magician takes the ordinary something and makes it do something extraordinary.”
Something Ordinary:
To Extraordinary:
Predict next token
and next token, next token, .........
Sourcing billions of tokens from the Internet is a massive engineering effort!!
Pre-Training
By doing this, the model eventually learns language structure, grammar and world knowledge !
Trillions of
Tokens
10 GB
5GB
21GB
40GB
1 GB
100 GB
1 TB
BookCorpus
Wikipedia
WebText(closed)
110GB
RealNews
800GB
The Pile
1.6 TB
ROOTS
2015
2019
2023
2020
Falcon
2.6TB
10 TB
5TB
RedPajama
11TB
DOLMA
2024
C4
Opportunity:
Build one
Challenge:
Inadequate quality datasets for Indic Languages
C4
ROOTS
DOLMA
mC4
Sangraha
Dataset Name
# of tokens
~156 Billion
Diversity
Webpage
~170 Billion
22 sources
> 1 Trillion
380 Programing languages
5 Trillion (600B in public)
Webpage
1.2/30 Trillion
Webpage, Books, Arxiv, Wiki, StackExch
3 Trillion
Webpage, Books, Wiki, The Stack, STEM
~418 Billion
Webpage
~341 Billion
natural and programming languages
251 Billion
Web, videos, digitized pdf,synthetic
Languages
English
English
Code
English
English/Multi
English
Multi
Multi
Multi
Effort by AI4Bharat
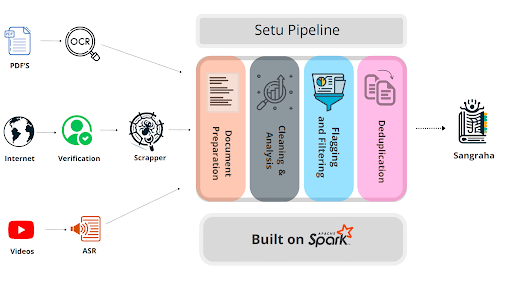


English data
Capture all India specific knowledge in all Indian Languages!
Billions of
Parameters





Fruit Fly
Honey Bee
Mouse
Cat
Brain
>10^6
10^9
10^{12}
10^{13}
10^{15}
# Synapses
400M
Transformer
1.5B
GPT-2
10B
Megatron LM
175B
GPT-3
GShard
1.1 T
1.6 T
Zetta FLOPS
of Compute
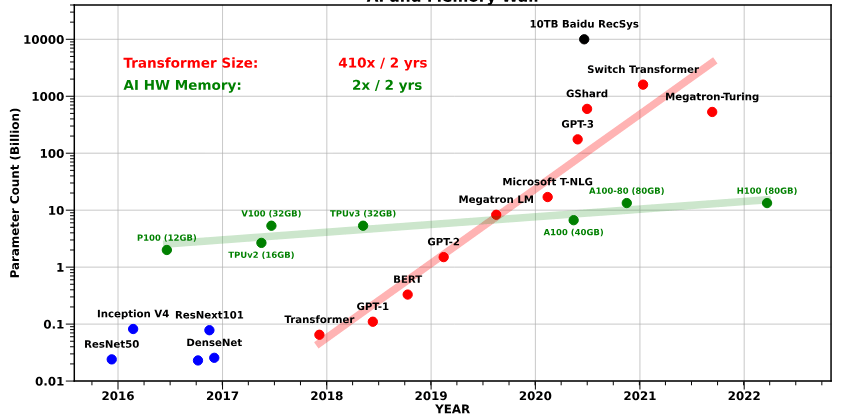
Training LLMs having more than 70 Billion Parameters is affordable only for a few organizations around the world
Requires a cluster of A100 (or) H100 GPUs that requires millions of dollars
Then, how do we adapt those models for diverse Indian culture and languages
Way to go: Language Adaptation ?
Trillions of
Tokens
Billions of
Parameters
Zetta FLOPS
of Compute
Pre-Trained open sourced LLM
+
+
Way to go: Language Adaptation ?
Trillions of
Tokens
Billions of
Parameters
Zetta FLOPS
of Compute
Pre-Trained open sourced LLM
+
+
Billions of
Tokens
Billions of
Parameters
Peta FLOPS
of Compute
Fully fine-tuned
+
+
Sangraha
Billions of
Parameters
Fruit Fly
Honey Bee
Mouse
Cat
Brain
>10^6
10^9
10^{12}
10^{13}
10^{15}
# Synapses
400M
Transformer
1.5B
GPT-2
10B
Megatron LM
175B
GPT-3
GShard
1.1 T
1.6 T
Affordable for inference
Opportunity:
Use Instruction Fine-tuning and build datasets for the same
Challenge:
(full) Fine-Tuning of LLMs on Indic datasets still requires a lot of compute and expensive
Way to go: Instruction Fine-Tuning?
Billions of
Tokens
Billions of
Parameters
Peta FLOPS
of Compute
Fully fine-tuned
+
+
Sangraha
LLMs exhibit a remarkable learning ability called "in context learning".
It means, we can instruct them to respond in certain way by giving them a set of examples about the task during inference [the cheapest option]
Way to go: Instruction Fine-Tuning
Millions of
Tokens
Billions of
Parameters
Tera FLOPS
of Compute
Instruction-tuned
+
+
Indic-Align
Goal:
Improve the model’s ability to understand and follow human instructions and ensure response is aligned with human expectations and values.
How it works:
Training the model on a set (relatively small) of high quality and diverse instruction and answer pairs.
How do we source the data?





From all the places where a conversation happens!
100 K
52K
64K
84K
<10K
500 K
Alpaca
Unnatural
Self-Instruct
143K
Evolved Instruct
What should be the size?
1M
10M
534K
Guanaco
620K
Natural Inst
1.5M
Ultra Chat
12M
P3
15M
FLAN
Significantly lesser
But more high quality!!
For Indian Languages ?


Existing English Data
Synthetic India-centric conversations

Indic-Align

Capture all different ways in which people can ask!!
Evaluation
How do we compare the performance of one model to the other?
How good is the model at solving a given task?
Are there any more hidden skills we dont know about?
Still a lot of open questions to explore here.
How good is the model in other languages?
Is the model biased? Is it Toxic? Is it Harmful?


There are hundreds of models in the market (ChatGPT, Llama, Gemma, Sutra ..)

What is the next big direction?

If a single architecture works for Text, Image, sound and video, then why not train the architecture on all these modalities?
...and it is already happening
That's called multi-modal LLM
Again, What about the data for Indian Context?
It is both a challenge and an opportunity!
Opportunities are Plenty
We now know that
-
Cost for Pre-training is prohibitive !
-
Cost for Fine-tuning is still expensive !
but running the model in inference mode is cheaper
-
Requires far less computing than pre-training and fine-tuning
-
One can access via APIs [No need to setup anything]
In inference mode, we can
-
Tune a model to do a new task via In-Context Learning (few-shot prompting)
-
Build apps that combine the power of LLMs with other tools to solve other problems!
We can build numerous applications !
Workshop Activity Details
Whats next?
-
Building an end to end voice-enabled Chatbot
-
Integrate the ASR, NMT and TTS models together with ChatGPT.
-
RAG-based pipeline to build a Govt. Scheme bot.
-
-
Help us build a real-world benchmark for evaluating LLMs in the Indian context and languages.
-
Take home activity
-
Just 25 prompts per person.
-
-
Certificates for the workshop will be given to attendees upon successfully
-
Completing the assigned 25 prompts
-
Building your own voice-enabled chatbot.
-


Image Credits
Opportunities-in-the-llm-field
By Arun Prakash




